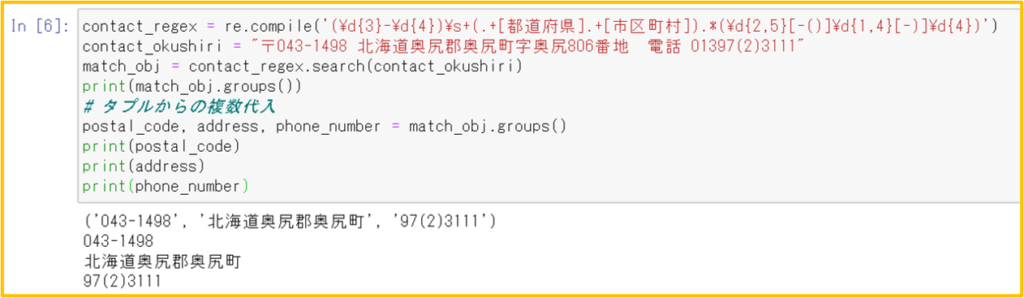
〖 課題 〗
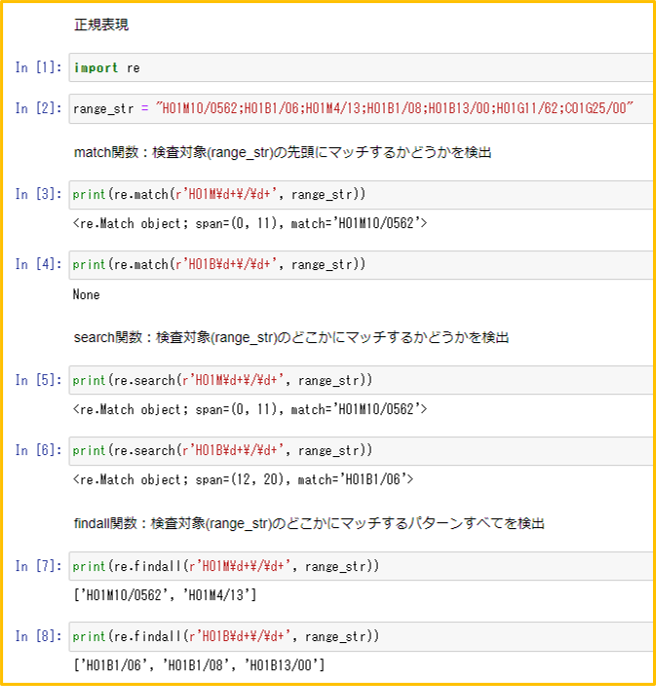
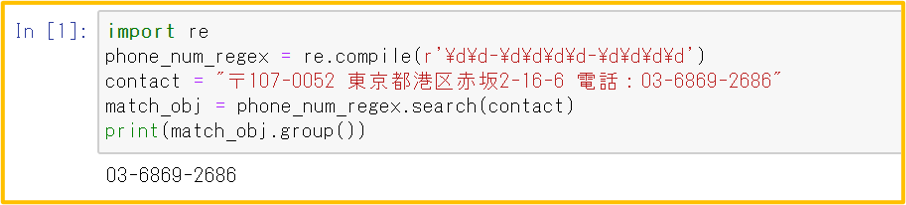
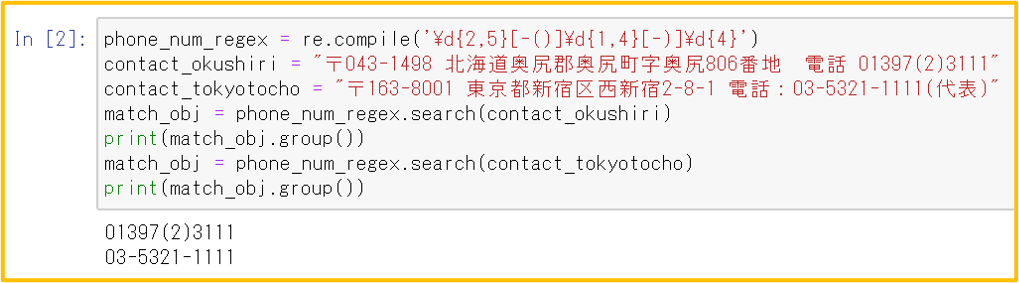
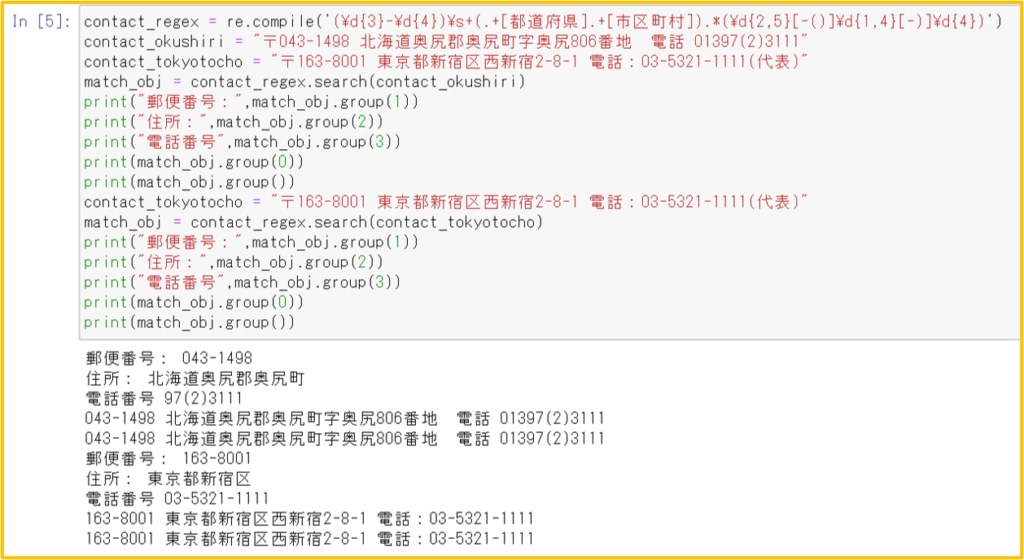
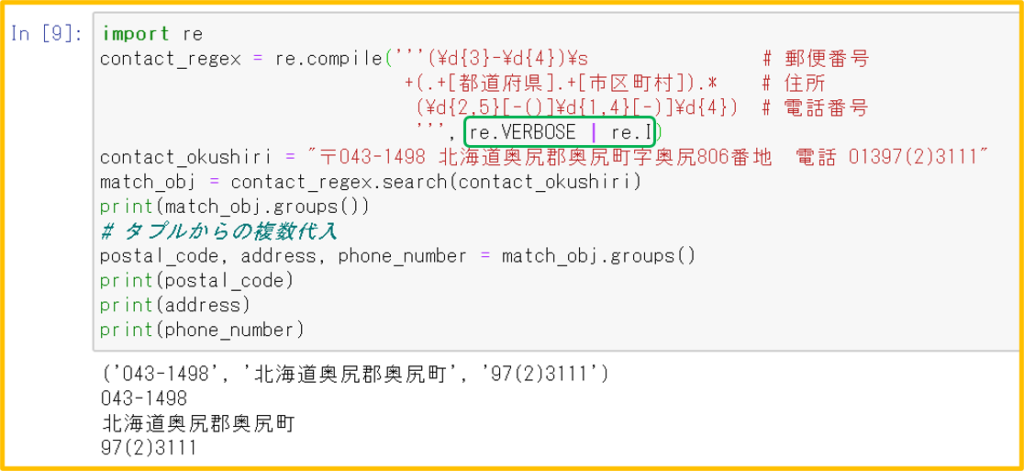
ダウンロードしたcsvファイルの特許文献リストから、発明者ごとに出願年と件数を抽出することによって、出願人がリストの特許分野に何人の発明者を投入したのかを知ることができる。
〖 仕様 〗
入力: 出力:
注:分割出願をカウントから除くためには改良が必要
〖 処理例 〗
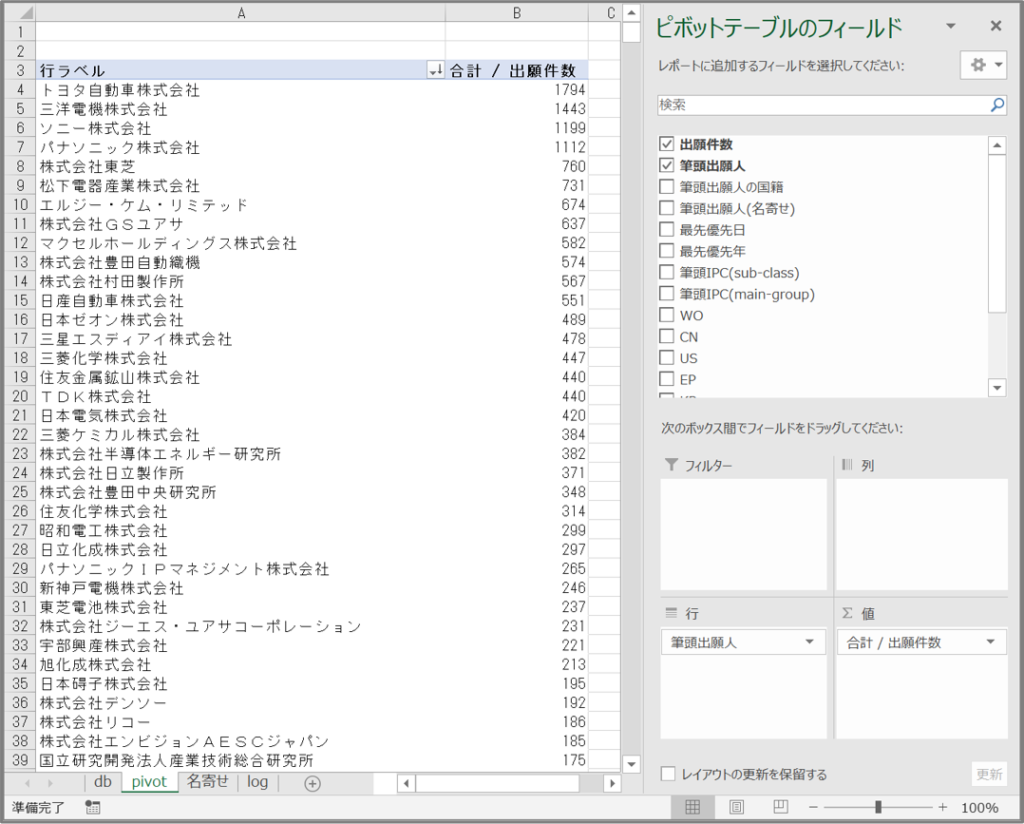
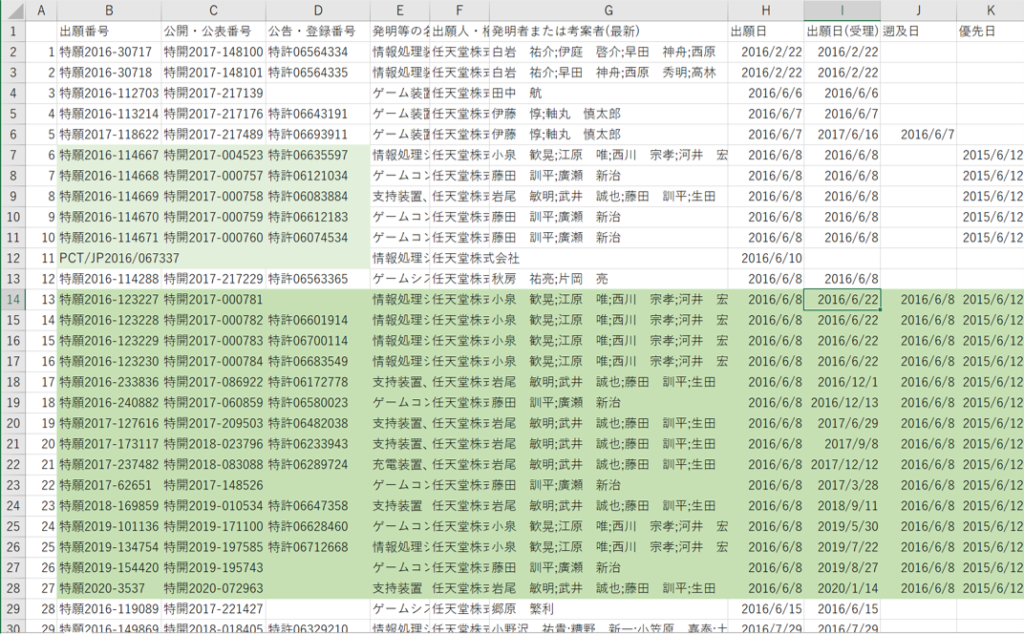
入力:
事例研究「任天堂スイッチの特許戦略(2020.9更新) 」で収集した任天堂スイッチの関連特許115件
発明者名は、複数のときは「; 」で区切られている。
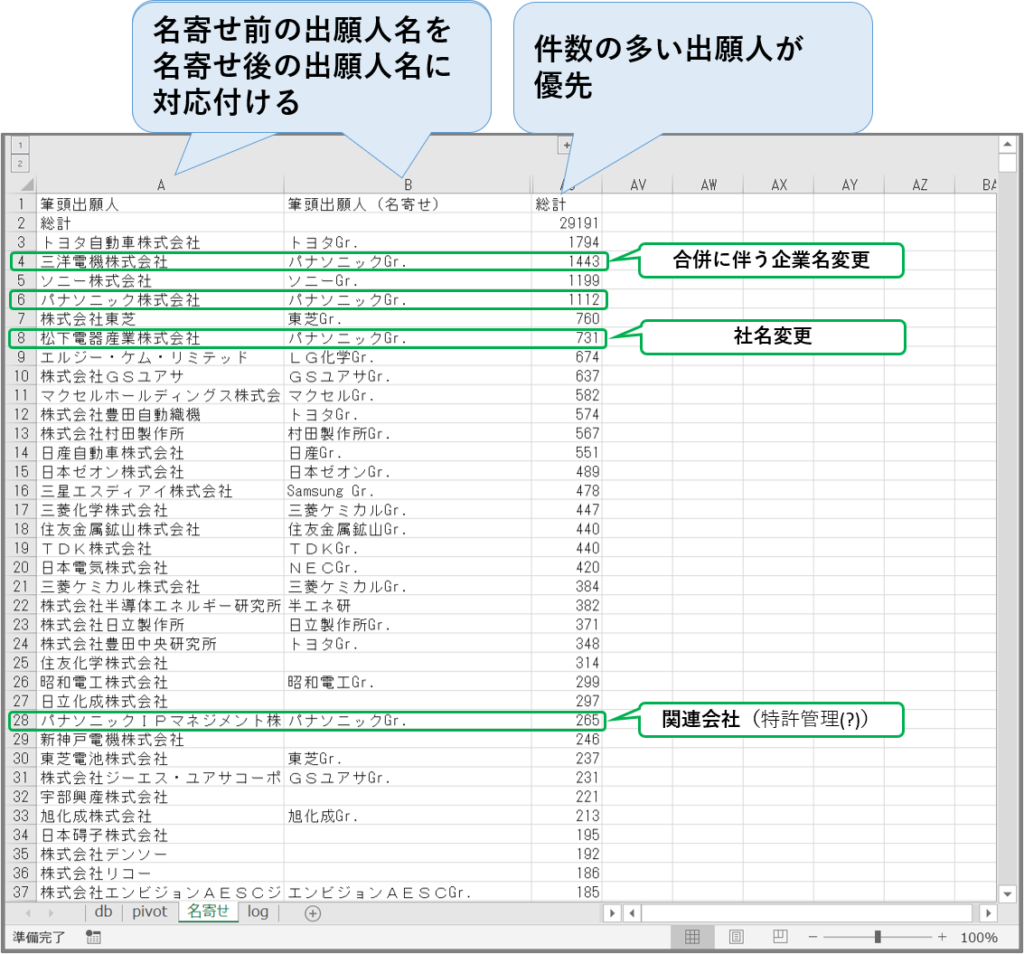
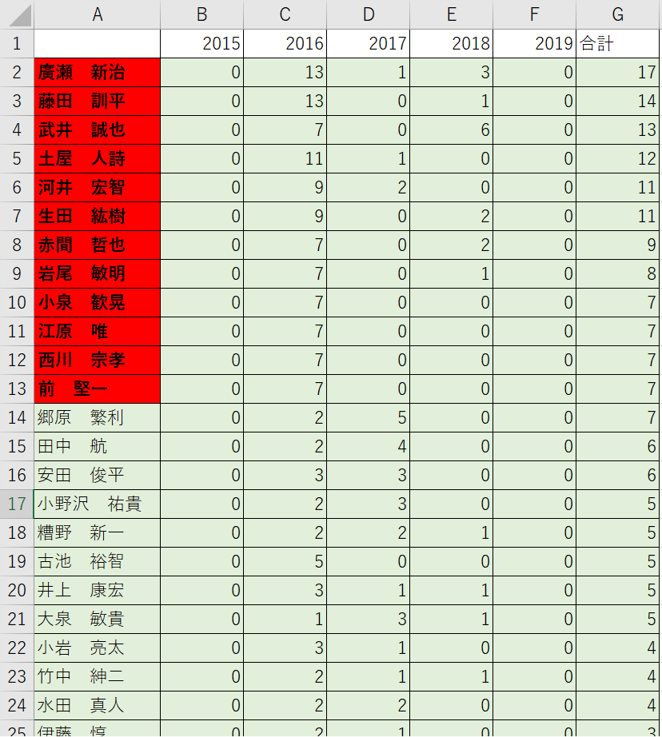
出力:
初めて出願した年の順に並べ替え、発明者の個人名を伏せて、件数をexcelの「条件付き書式」で色分けして示した。 中核メンバーが誰か、長く従事しているのか、新規に投入された人はその後も継続的に従事しているのかがわかる。ただし、任天堂スイッチの事例では、出願年の範囲がまだ狭く、あまり明確には顕れていない。
詳しくは、事例研究「任天堂スイッチの特許戦略(2020.9-10更新) 」に、「発明者分析を追加(2020.10.9)」を追加して更新した(ご参考)。
《 プログラムの構成 》
<入力>
<出力>
注:csvデータの数(特許文献数)、出願年の範囲などを固定値としてプログラム
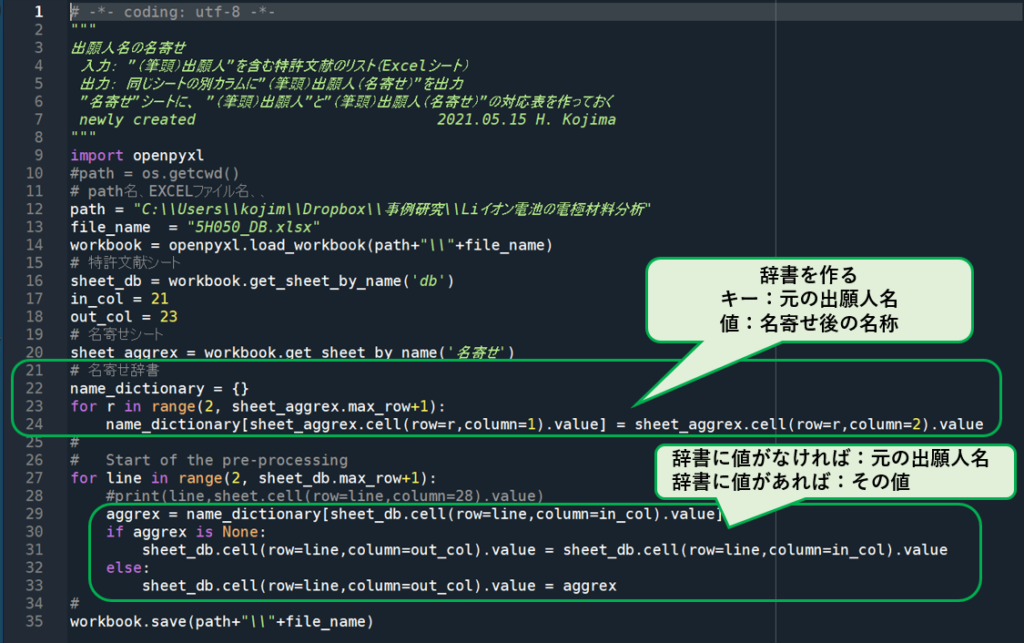
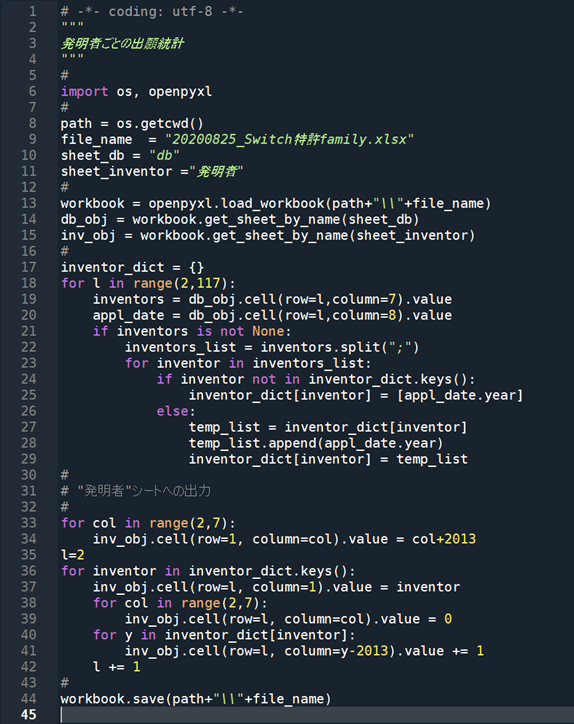
line 6: os, openpyxlを使用。osはgetcwdでpathを取得するため、openpyxlはexcelファイルを扱うため
line 8-11: ファイル名、シート名などのパラメータ指定
line 13-15: excelファイルを開き、2つのシート(csvデータ”db”と出力用の”発明者”シート)をオブジェクト化
line 17: inventor_dict=発明者の辞書(発明者名をkey、出願年のリストを値とする辞書型データ;出願年は複数になるので単独の整数ではなくリスト型とする)
line 18-29:csvデータの115件の特許文献情報を順次取得して処理するループ
line 19-20:ある1件の特許について、発明者(inventors)情報と出願日(appl_date)情報を取得; “区切りで連結された長い文字列
line 21-22:発明者(inventors)が空白でなければ、”; “で分割してリスト型に変換
line 23-29:その特許(line18のループで1件ずつ選ばれている特許)のすべての発明者について繰り返すループ
line 24-29:line 23のループで指している発明者が、inventor_dict(発明者の辞書)のkeyに既に存在するかどうかを調べ、
ここまででデータ解析は完了
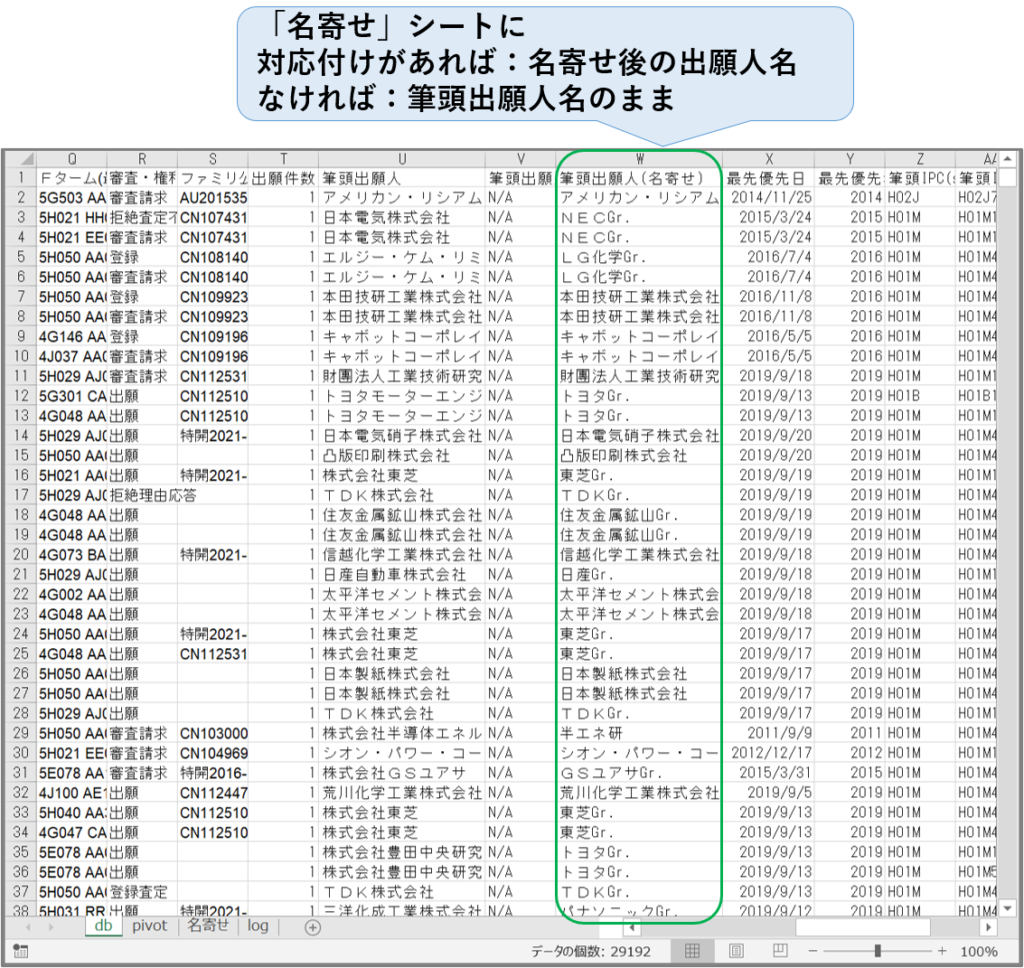
line 30-42:”発明者”シートへの出力
〖 プログラムソース 〗
# -*- coding: utf-8 -*-
"""
発明者解析
"""
#
import os, openpyxl
#
path = os.getcwd()
file_name = "20200825_Switch特許family.xlsx"
sheet_name = "発明者検索"
sheet_SW = "db172" # SWITCH特許
#
# シートオブジェクトを生成
workbook = openpyxl.load_workbook(path+"\\"+file_name)
sheet_obj = workbook.get_sheet_by_name(sheet_name)
SWpat_obj = workbook.get_sheet_by_name(sheet_SW)
#
# SWITCH特許のリストを作成
SWpatents = []
for i in range(2,173):
SWpatents.append(SWpat_obj.cell(row=2,column=i).value)
#
# SWITCH発明者のリストを作成
SWinventors = []
for i in range(29,172):
SWinventors.append(sheet_obj.cell(row=2,column=i).value)
#
# "発明者検索"シートでの解析
for l in range(3,sheet_obj.max_row+1):
# 共同出願解析
applicants = sheet_obj.cell(row=l,column=7).value
if "任天堂" in applicants:
if ";" in applicants:
sheet_obj.cell(row=l,column=24).value = applicants.replace("任天堂株式会社","N")
else:
sheet_obj.cell(row=l,column=23).value = 1 # 任天堂単独出願
# SWITCH特許か否かの判定
appl_num = sheet_obj.cell(row=l,column=2).value
if appl_num in SWpatents:
sheet_obj.cell(row=l,column=25).value = 1 # SWITCH特許
# 発明者解析
inventors = sheet_obj.cell(row=l,column=8).value
if inventors is None:
sheet_obj.cell(row=l,column=26).value = 0 # 発明者数
else:
inventor_list = inventors.split(";")
sheet_obj.cell(row=l,column=26).value = len(inventor_list) # 発明者数
num_SWinv = 0
for inventor in inventor_list:
for col in range(29,172):
if inventor == SWinventors[col-29]:
num_SWinv +=1
sheet_obj.cell(row=l,column=col).value = 1 # SW発明者のフラグ処理
sheet_obj.cell(row=l,column=27).value = num_SWinv # SW発明者数
sheet_obj.cell(row=l,column=28).value = len(inventor_list) - num_SWinv
#
workbook.save(path+"\\"+file_name)