〘 課題 〙
「名寄せ」とは、表記を一つにまとめること。出願人名は、企業、団体、学校、研究機関、個人などの名称で、主体が同じでも完全に統一されていて変更されないというわけではない。例えば、会社名の変更、合併などで名称が変更されることがある。それ以外にも、関連会社などので1つのグループとして扱った方が良い場合もある。
〘 仕様 〙
処理対象:EXCELの特許文献リスト(「”db”シート」とする)
「csvの前処理」を使って抽出した「筆頭出願人」カラムを持つことを想定
入力:「筆頭出願人」カラム
出力:「筆頭出願人(名寄せ)」カラム
「名寄せ」シート: 「筆頭出願人」と「筆頭出願人(名寄せ)」の対応付け
〘 名寄せシートの作り方 〙
「”db”シート」から「筆頭出願人」のピボットテーブルを作成
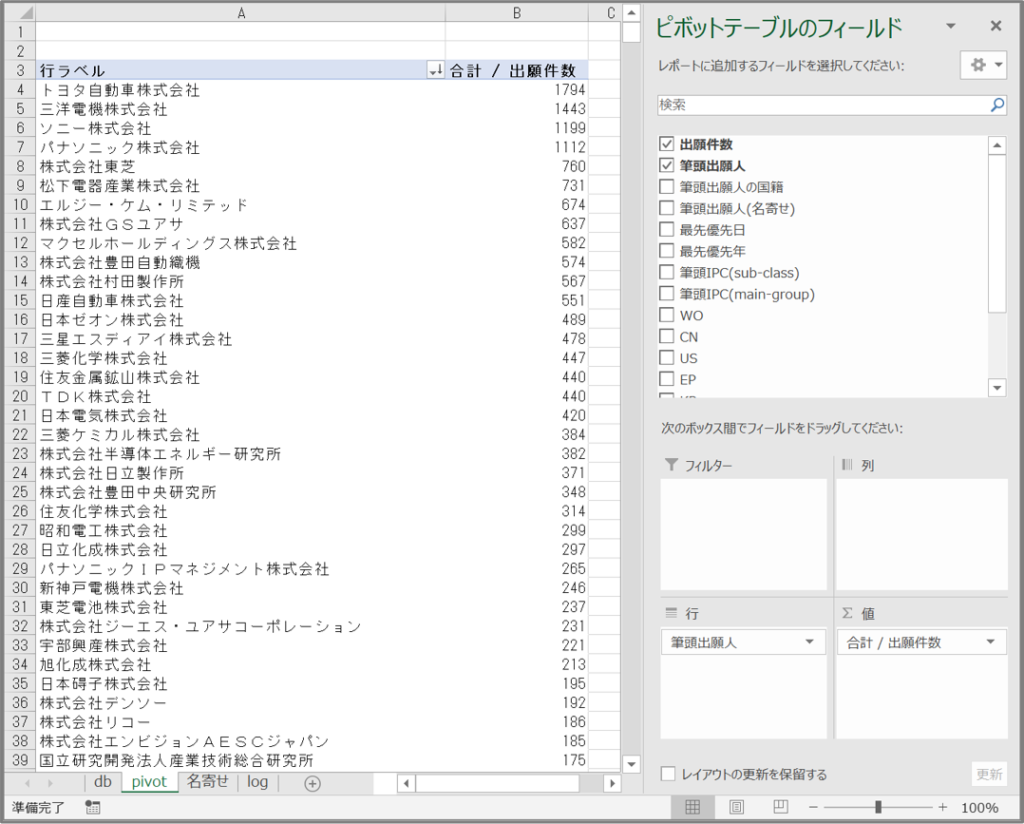
EXCELの「ピボットテーブル」を使うのは必須ではないが、出願件数の多い「筆頭出願人」を優先して、どのような名称を名寄せするかを検討する。
これをコピーして「名寄せ」シートを作成
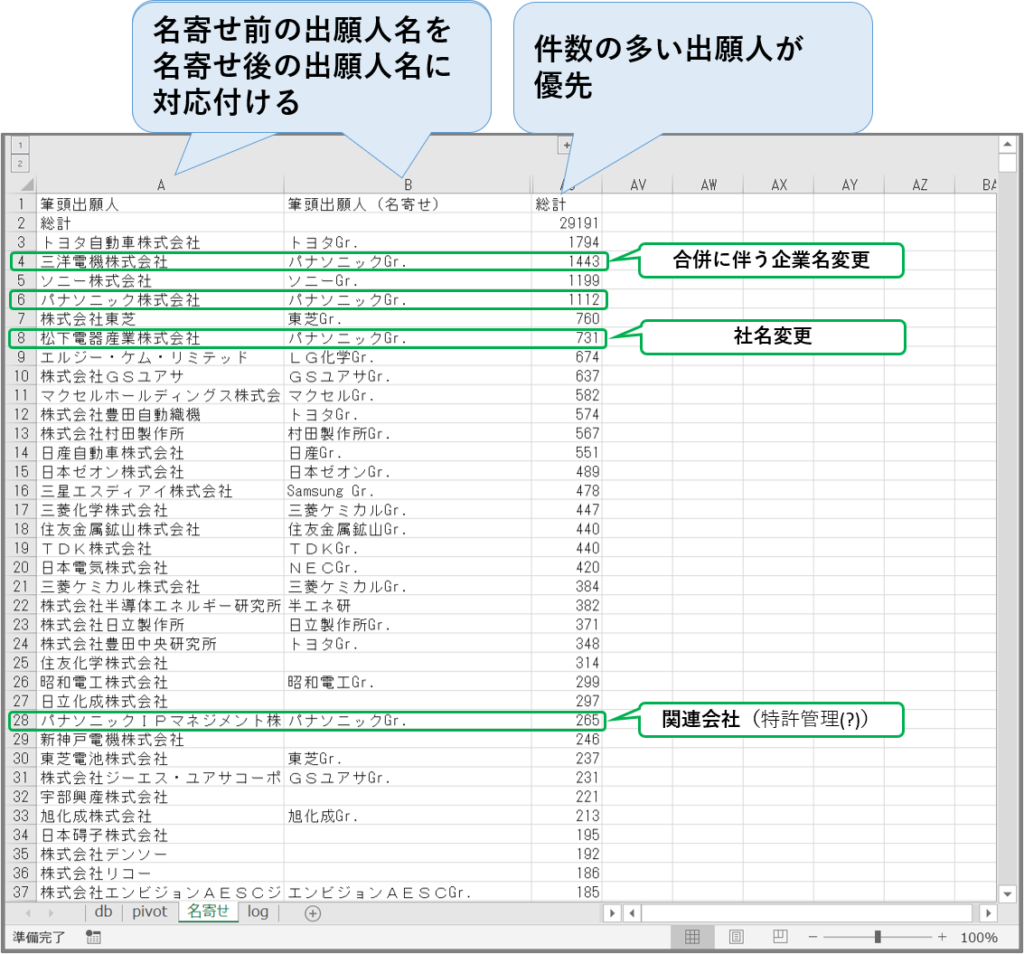
名寄せ前の出願人名(Aカラム)を名寄せ後の出願人名(Bカラム)に対応付ける作業
出願件数の多い出願人名を優先して行い、上位何社(何人)まで行うかは、分析の目的による。
上の「パナソニックGr.」のように、「三洋電機」との合併、「松下電器産業」からの社名変更、「パナソニックIPマネージメント株式会社」などの関連会社など、まとめて扱いたいグループごとに、名寄せ後の出願人名を統一する。
名寄せ辞書の作成も、AIを活用するなどで自動化したいが、まだまだ検討中……
現段階では、マニュアルで進めるしかない。
〘 pythonによる処理 〙
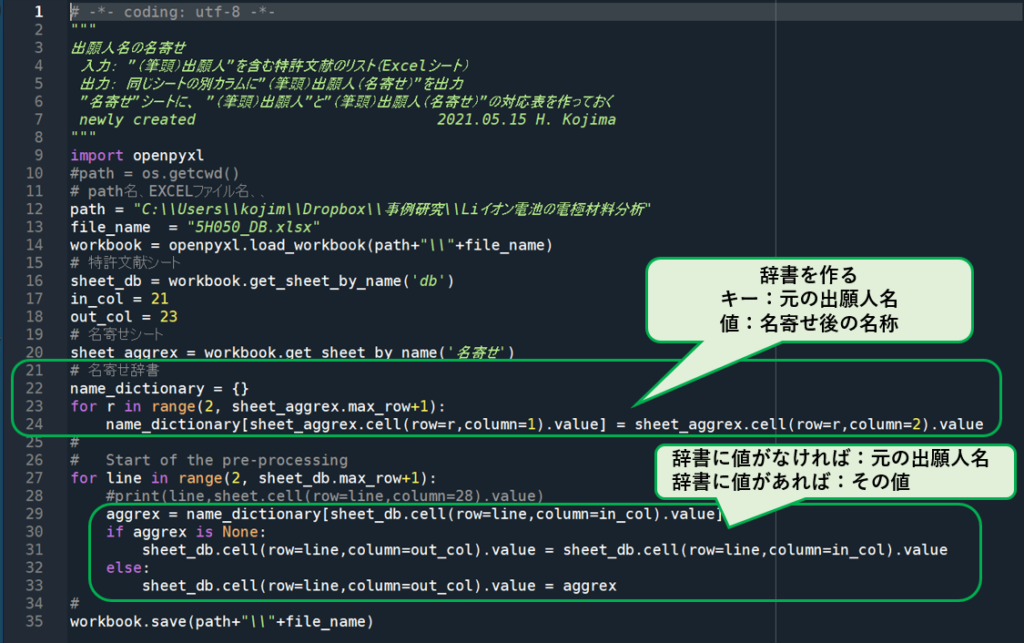
〘 プログラムのポイント 〙
① 「名寄せ」シートを参照して、「名寄せ辞書」”name_dictionary”を作成。
キー:元の出願人名
値:名寄せ後の名称(空欄なら値は”None”)
(「辞書」については、 基礎-2 リスト、タプル、辞書 を参照。)
② ”db”シートの各行(各特許文献)について、「筆頭出願人」が「名寄せ辞書」のキーのどれかに一致するので、値があればその値(名寄せ後の出願人名)、値がなければ(None)「筆頭出願人名」をそのまま、「筆頭出願人(名寄せ)」のカラムに出力する。
〘 処理結果 〙
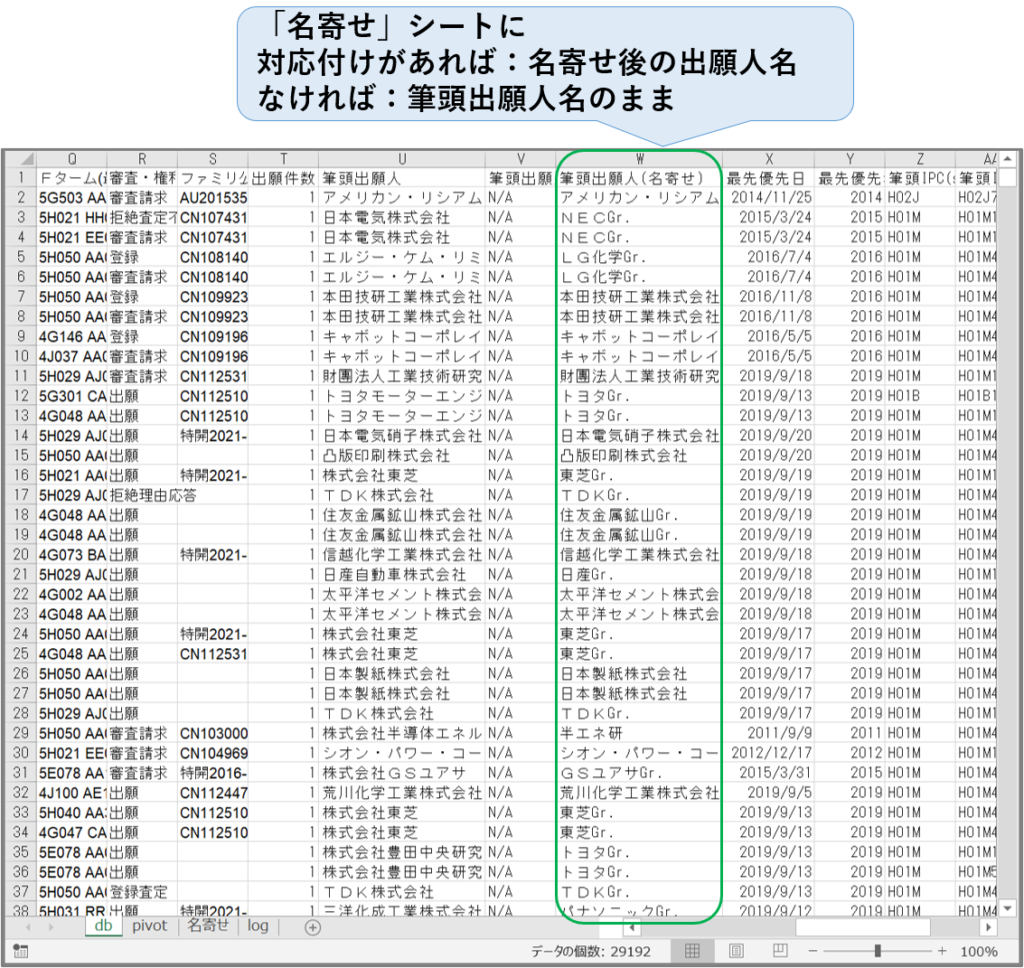
出願人名を名寄せした後で、もう一度ピボットテーブルを作ると、出願人グループごとに出願件数を集計することができる。