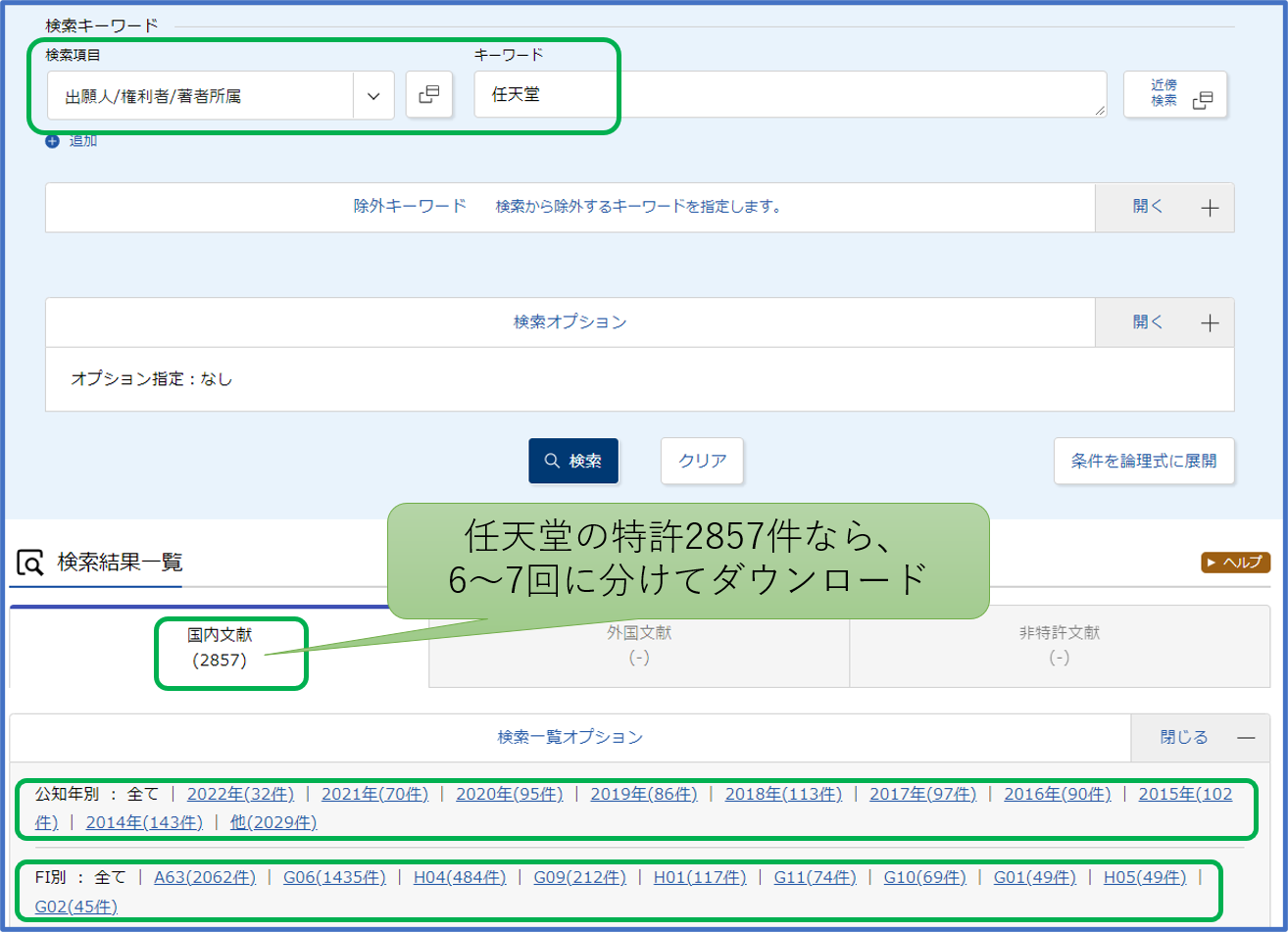
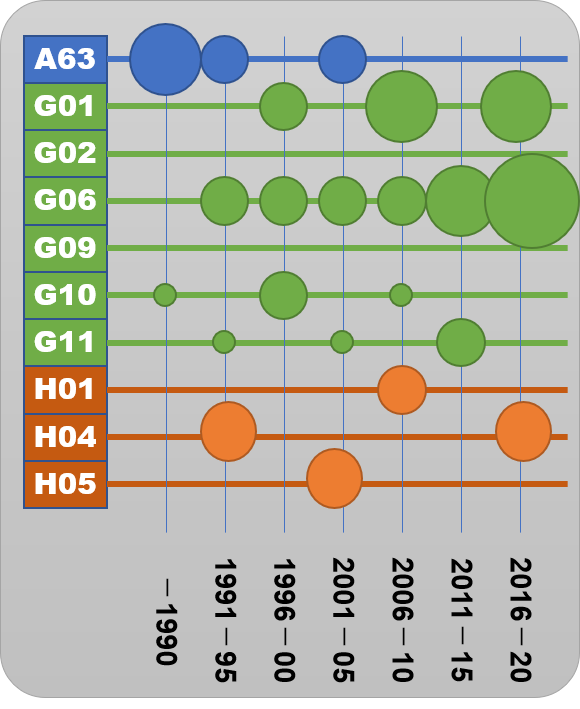
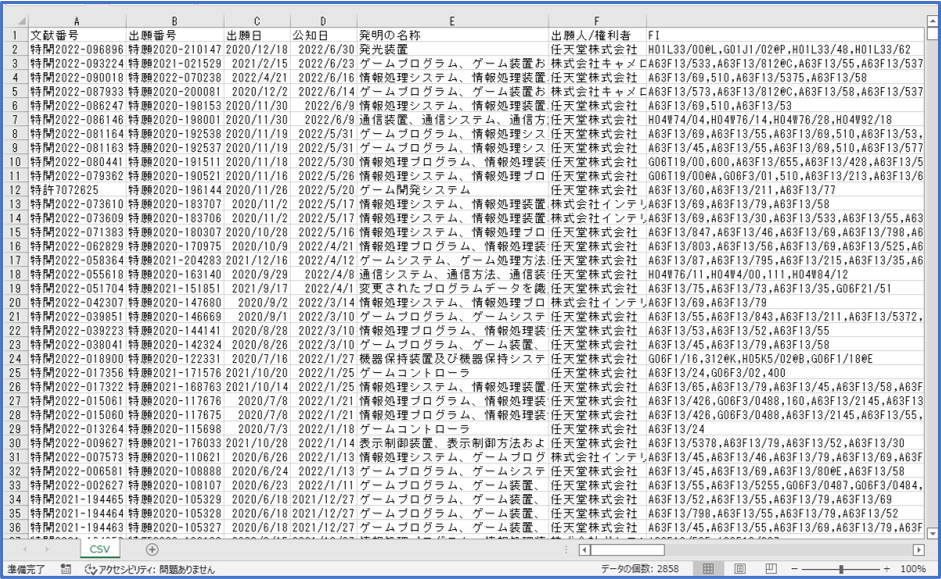
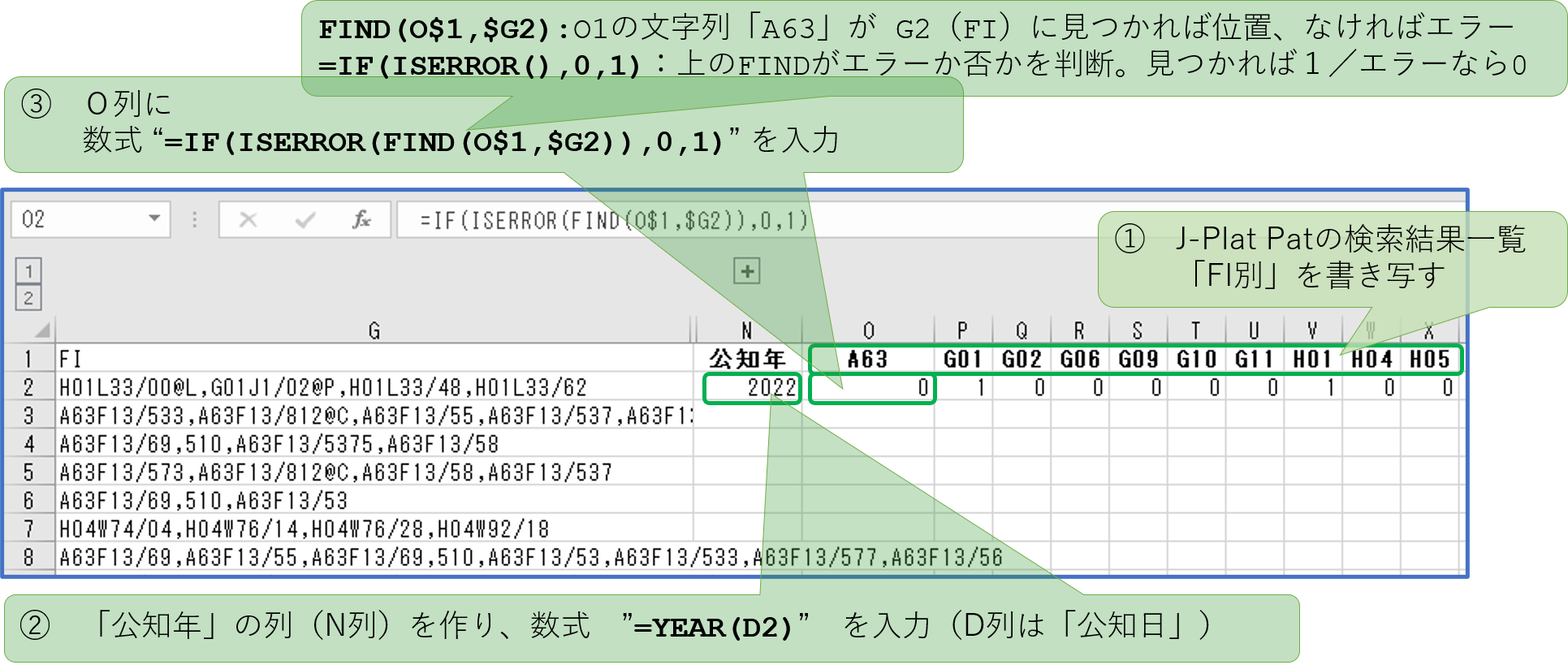
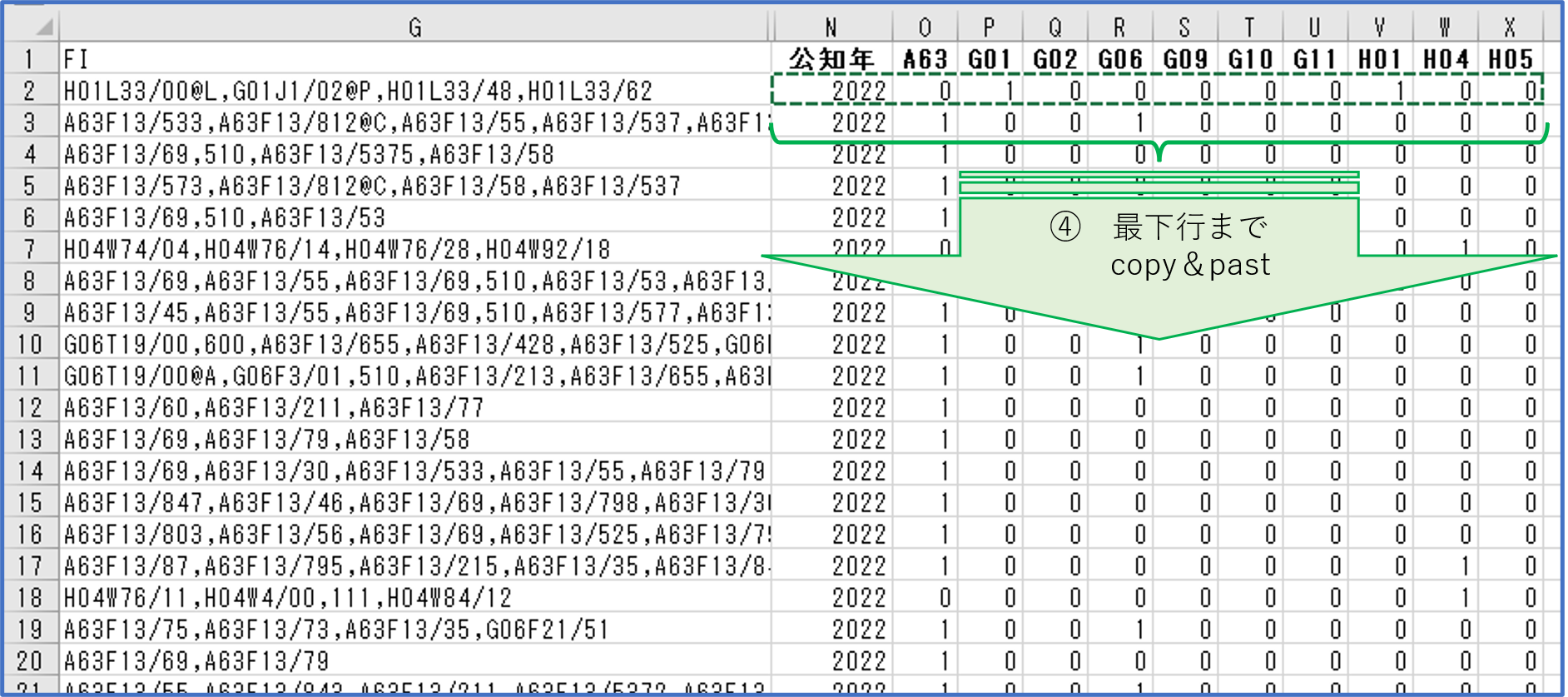
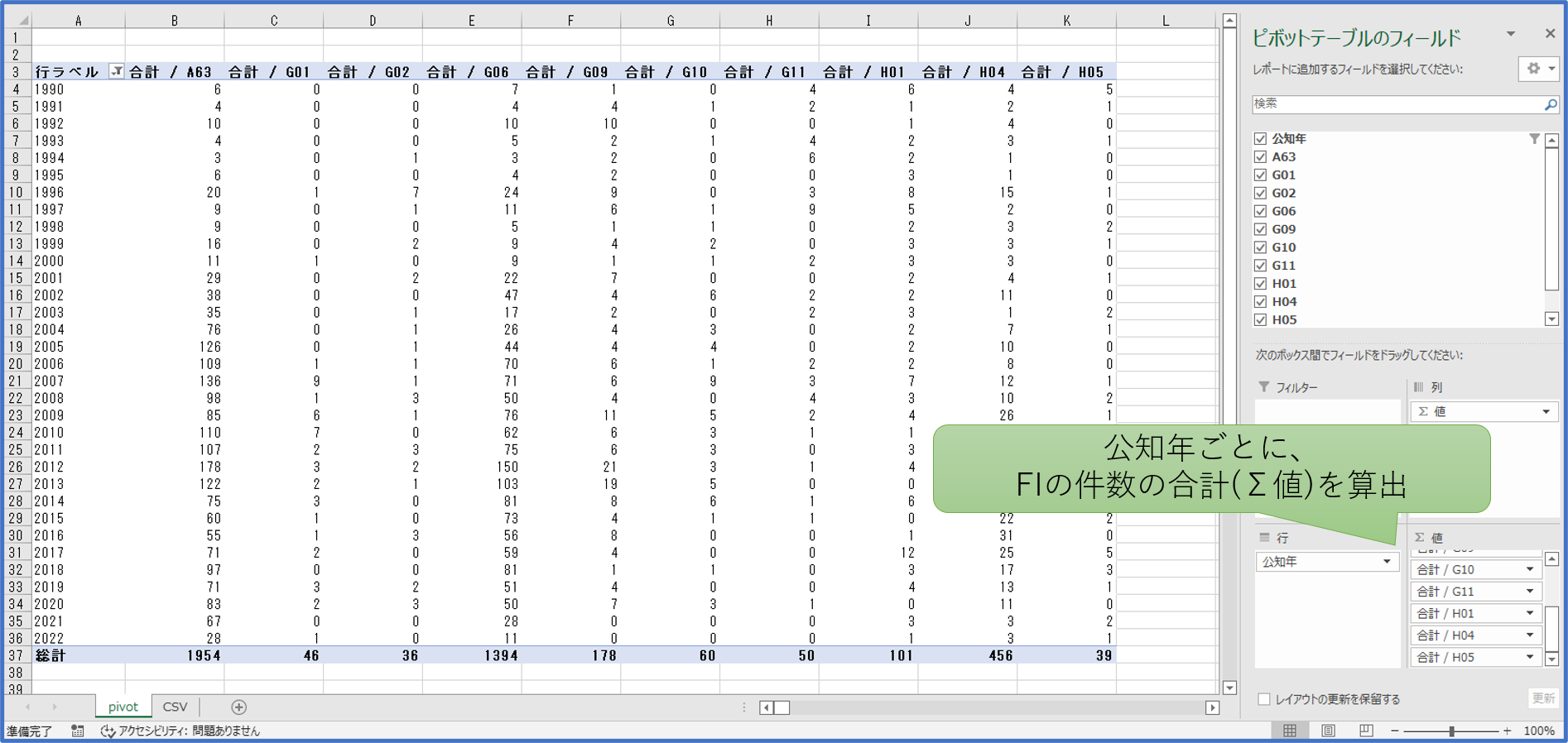
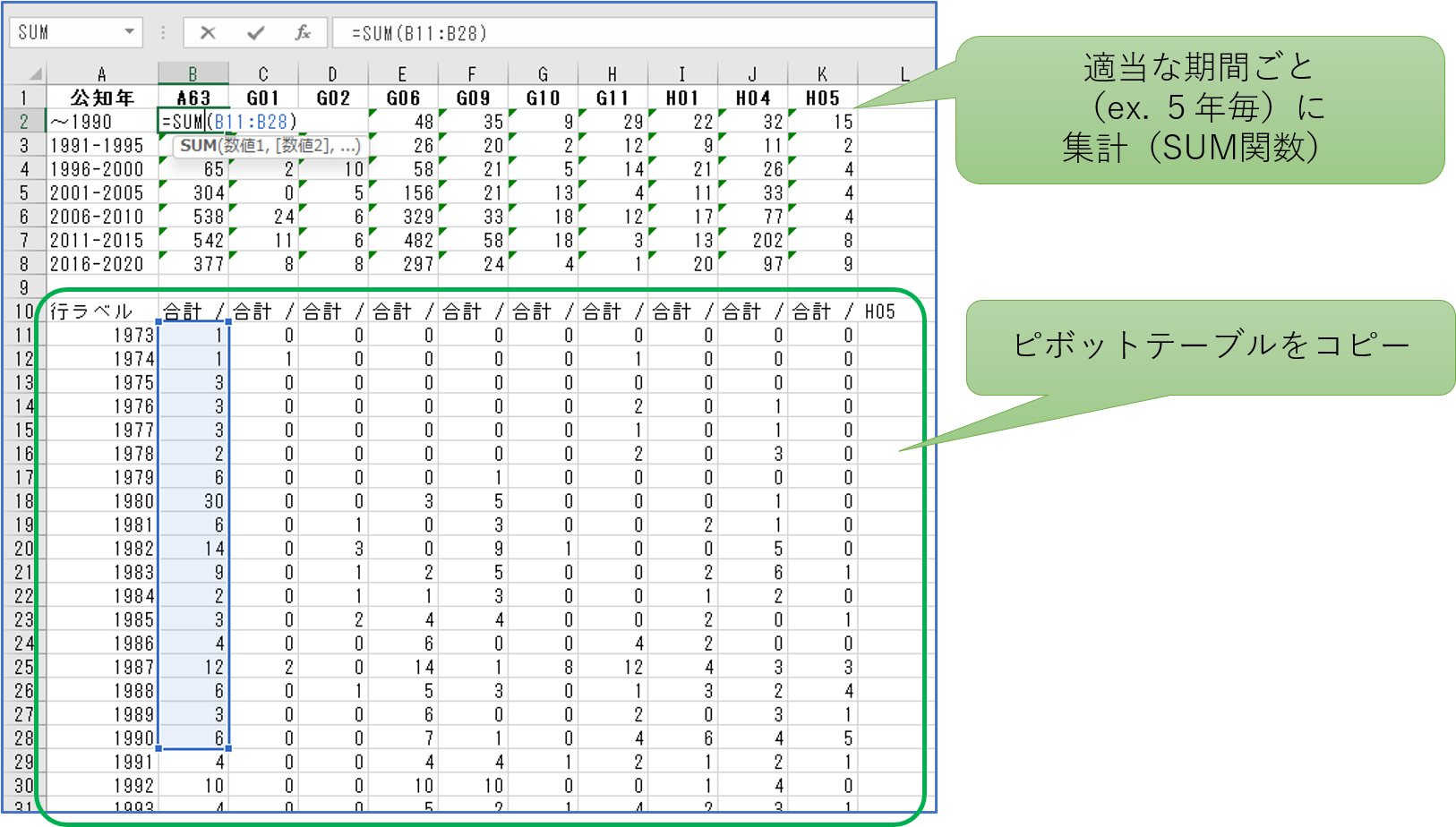
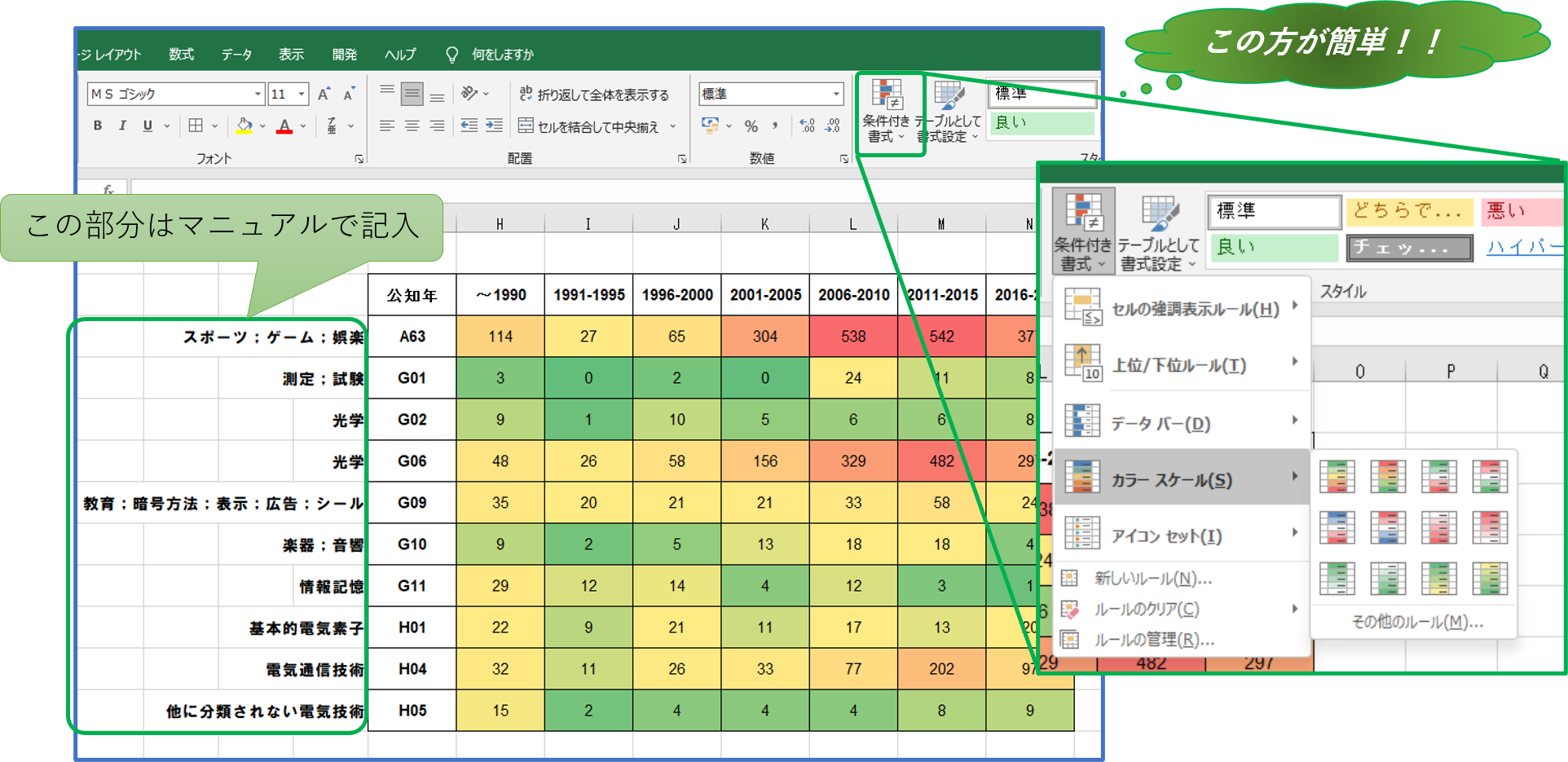
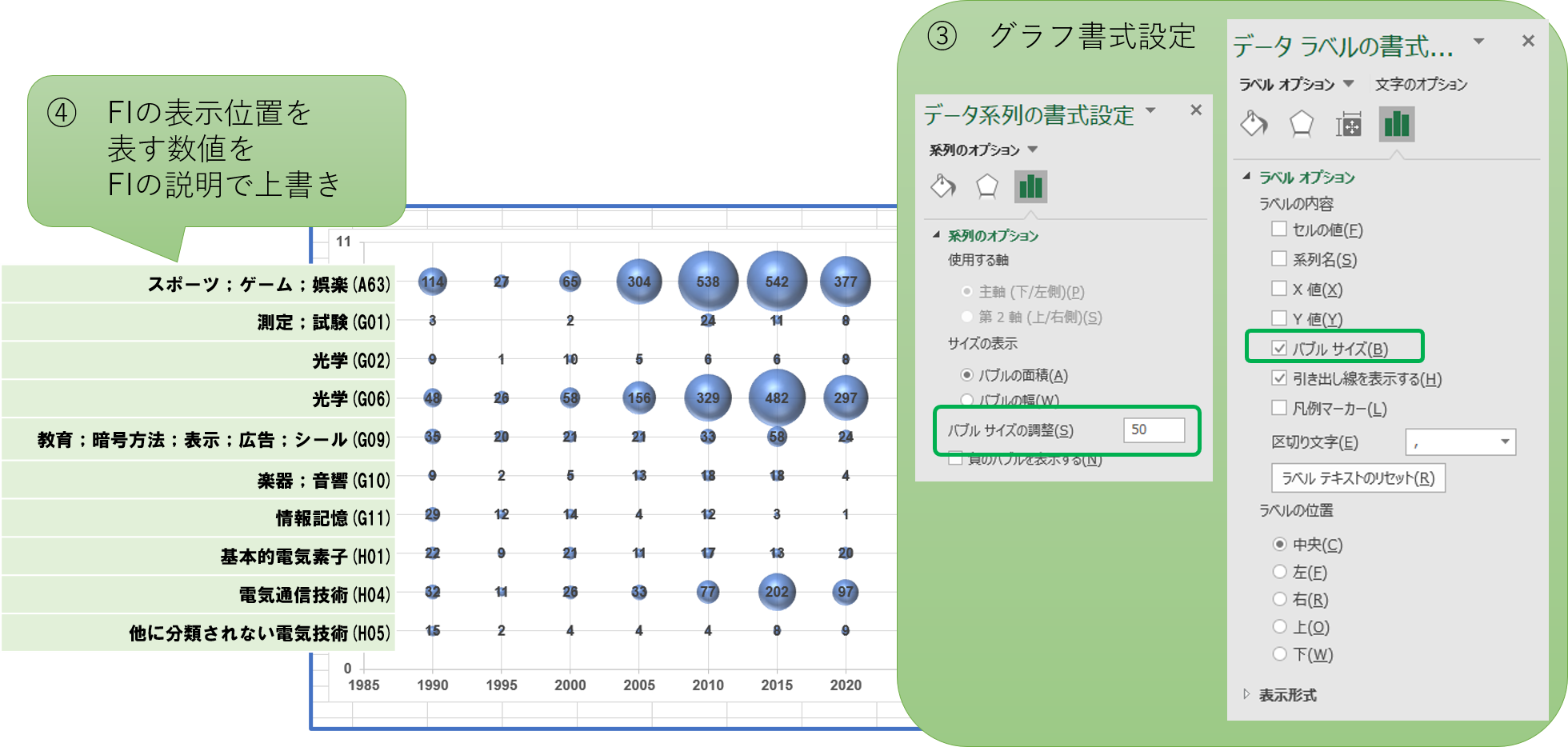
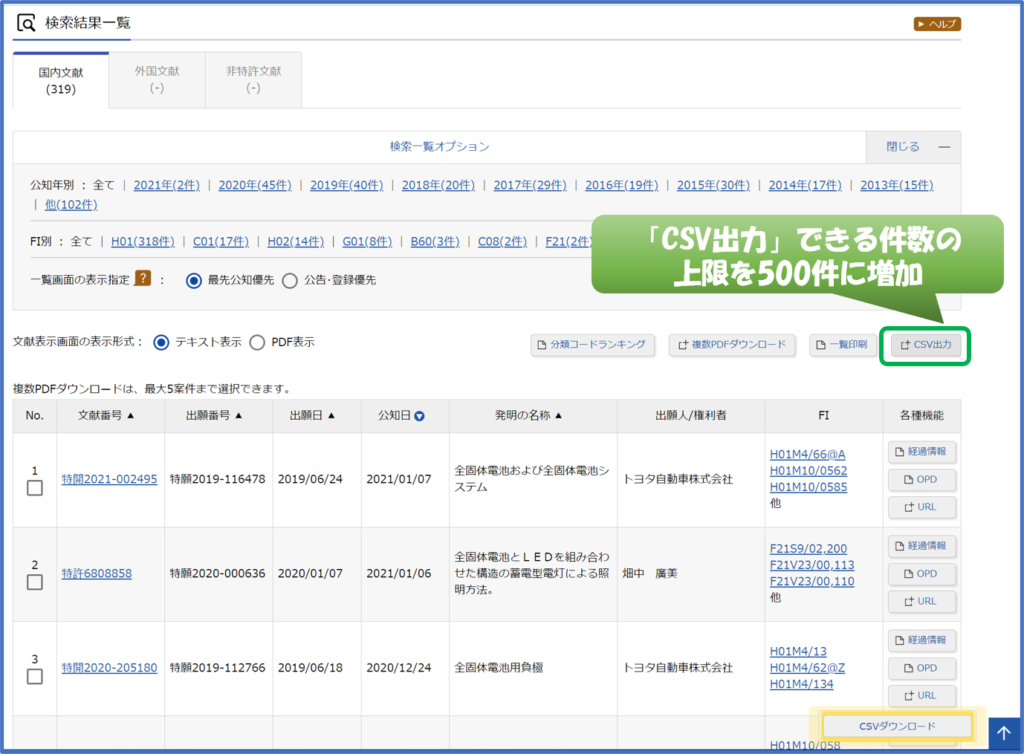
《 前処理の目的と内容 》
csvダウンロードした特許情報ファイルを編集して、分析に便利な情報を追加する前処理
-
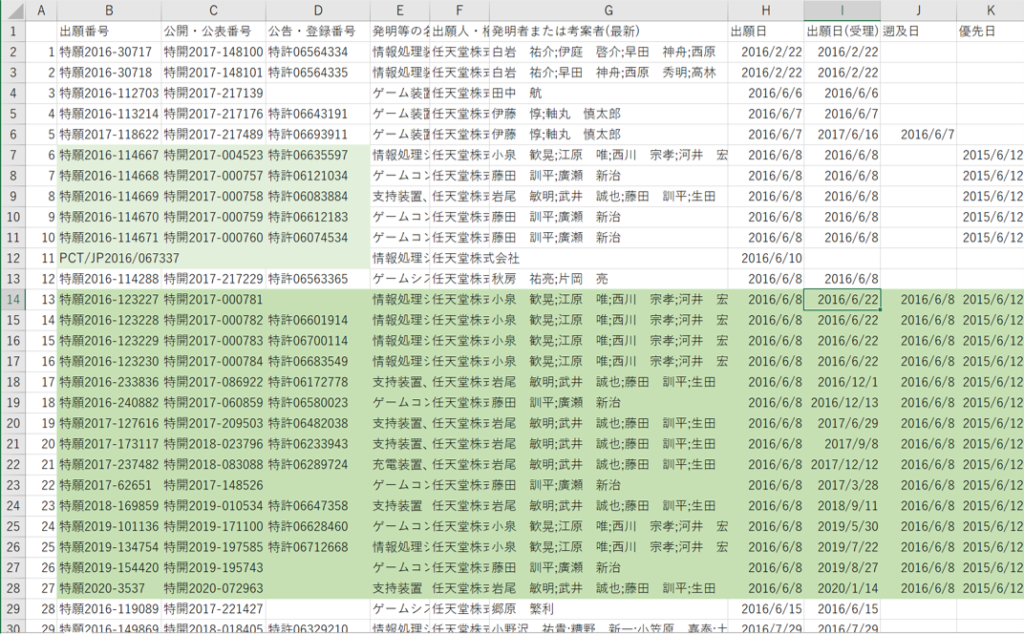
〈出願件数〉
「出願件数」の列(column)を作って、出願件数として全ての行(row)に「1」を入力
-
〈筆頭出願人(出願人分析用)〉
「出願人」欄から、筆頭出願人を抽出。国籍(アルファベット2文字の国コード)が括弧書きされているとき、「出願人の国籍」の列(column)に出力。さらに抽出した「筆頭出願人」と同じデータを「筆頭出願人(名寄せ)」にコピー。「筆頭出願人(名寄せ)」は将来の名寄せ用の元データ。
-
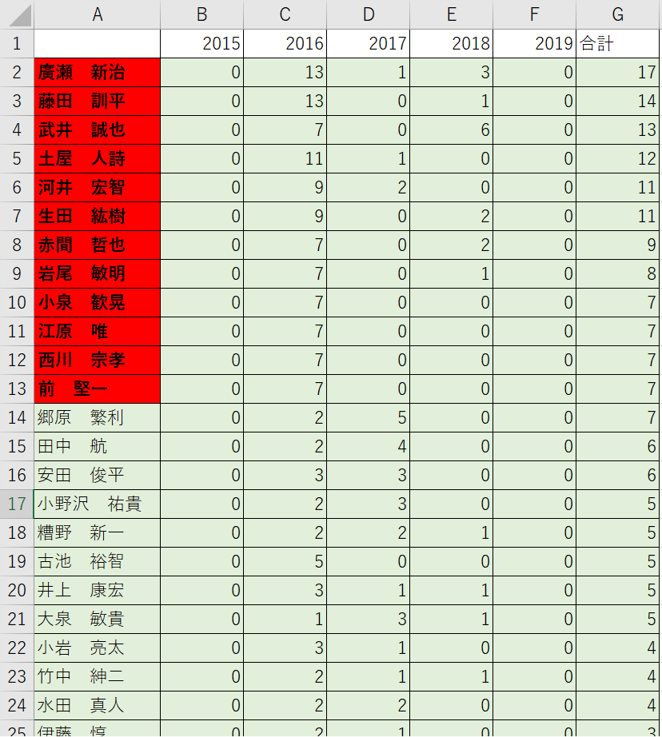
〈最先の優先日(年次推移分析用)〉
「最先優先日」と「最先優先年」の列(column)を追加。「出願日」と「優先日」の欄から最先の日を抽出して「最先優先日」として出力。さらに、抽出した「最先優先日」からその年を抜き出して「最先優先年」として出力。
-
〈筆頭IPC(技術分野分析用)〉
「筆頭IPC(sub-class)」と「筆頭IPC(main-group)」の列(column)を追加。「IPC」の欄から、筆頭IPCを抽出して、サブクラス(先頭の4文字,”H01L”など)を「筆頭IPC(sub-class)」に、メイングループ(先頭の4文字,”H01L”などに続く「数字/数字」の前半部分)を「筆頭IPC(main-group)」に出力。
-
〈出願国(出願国分析用)〉
「JP」「WO」「US」「EP」「CN」「KR」の列(column)を追加。「ファミリー公報」の欄から、作成した列(column)に相当する国・地域への出願があれば「1」なければ「0」を出力。その国・地域への出願の有無を表すフラグ。同じ国・地域内でのファミリー展開に応じた件数は無視して、単に有無のみを判定。
《 プログラムの構成 》
<入力>
csvダウンロードしたデータから構成したEXCELファイル
複数シートを想定して、シート名を指定して処理
<出力>
指定したシート内への列(column)の追加
<プログラム>
上記1~5は関数として定義。処理対象のWokkBook名(EXCELファイル名)とシート名を指定して必要な前処理を実行する関数を呼び出す。
# -*- coding: utf-8 -*-
"""
csvDLから作成したEXCELテーブルの前処理
2020.07.18 newly created
"""
#
import re, os, openpyxl, datetime
#
# 関数定義
#
# 出願件数(1固定)
def num_application(file_name, sheet_name, col_n_apl):
global path
global col_out_start
workbook = openpyxl.load_workbook(path+"\\"+file_name)
sheet = workbook.get_sheet_by_name(sheet_name)
print("Processing 出願件数 for file = ", file_name, " sheet = ", sheet_name)
# header
sheet.cell(row=1,column=col_out_start).value = '出願件数'
#
for line in range(2, sheet.max_row+1):
sheet.cell(row=line,column=col_out_start).value = 1
#
col_out_start = col_out_start +1
workbook.save(path+"\\"+file_name)
#
# 筆頭出願人
# 国籍は、出願人欄に括弧書きで国コードが付されていることが前提
# 名寄せ欄は、筆頭出願人欄と同じ。後の名寄せ処理のため。
#
def applicant(file_name, sheet_name, col_n_apl):
global path
global col_out_start
regex_CC = re.compile(r'\(([A-Z][A-Z])\)') # Regex. of Country Code
#
workbook = openpyxl.load_workbook(path+"\\"+file_name)
sheet = workbook.get_sheet_by_name(sheet_name)
print("Processing 筆頭出願人 for file = ", file_name, " sheet = ", sheet_name)
# header
sheet.cell(row=1,column=col_out_start).value = '筆頭出願人'
sheet.cell(row=1,column=col_out_start+1).value = '筆頭出願人の国籍'
sheet.cell(row=1,column=col_out_start+2).value = '筆頭出願人(名寄せ)'
#
for line in range(2, sheet.max_row+1):
applicants = sheet.cell(row=line,column=col_n_apl).value.split(';')
if type(applicants is list):
applicant = applicants[0]
else:
applicant = applicants
CC = regex_CC.search(applicant)
if CC is None:
Nationality = 'N/A'
else:
Nationality = CC.group(1)
applicant = applicant[0:CC.start()-1]
sheet.cell(row=line,column=col_out_start).value = applicant
sheet.cell(row=line,column=col_out_start+1).value = Nationality
sheet.cell(row=line,column=col_out_start+2).value = applicant
#
col_out_start = col_out_start +3
workbook.save(path+"\\"+file_name)
#
# 最先の優先日とその年の抽出
# 最先の優先日: 出願日と優先日(複数優先も想定)のうち最先の日
#
def earliest_date(file_name, sheet_name, col_d_apl, col_d_pri):
global path
global col_out_start
workbook = openpyxl.load_workbook(path+"\\"+file_name)
sheet = workbook.get_sheet_by_name(sheet_name)
print("Processing 最先優先日 for file = ", file_name, " sheet = ", sheet_name)
# header
sheet.cell(row=1,column=col_out_start).value = '最先優先日'
sheet.cell(row=1,column=col_out_start+1).value = '最先優先年'
#
for line in range(2, sheet.max_row+1):
pp_date = sheet.cell(row=line,column=col_d_apl).value # Apllication date
if sheet.cell(row=line,column=col_d_pri).value is not None: # Priority dates
if type(sheet.cell(row=line,column=col_d_pri).value) is str:
p_dates = sheet.cell(row=line,column=col_d_pri).value.split(';')
for p_date in p_dates:
if datetime.datetime.strptime(p_date, '%Y/%m/%d') < pp_date:
pp_date = datetime.datetime.strptime(p_date, '%Y/%m/%d')
else:
p_date = sheet.cell(row=line,column=col_d_pri).value
if p_date < pp_date:
pp_date = p_date
sheet.cell(row=line,column=col_out_start).value = pp_date
sheet.cell(row=line,column=col_out_start+1).value = pp_date.year
#
col_out_start = col_out_start +2
workbook.save(path+"\\"+file_name)
#
# 筆頭IPCのサブセクション、メイングループまでの抽出
#
def primary_IPC(file_name, sheet_name, col_IPC):
global path
global col_out_start
workbook = openpyxl.load_workbook(path+"\\"+file_name)
sheet = workbook.get_sheet_by_name(sheet_name)
print("Processing 筆頭IPC for file = ", file_name, " sheet = ", sheet_name)
# header
sheet.cell(row=1,column=col_out_start).value = '筆頭IPC(sub-class)'
sheet.cell(row=1,column=col_out_start+1).value = '筆頭IPC(main-group)'
#
for line in range(2, sheet.max_row+1):
IPC = sheet.cell(row=line,column=col_IPC).value
if IPC is None:
IPC_class = 'N/A'
IPC_group = 'N/A'
else:
IPC_class = IPC[0:4]
IPC_group = IPC[0:IPC.find('/')]
sheet.cell(row=line,column=col_out_start).value = IPC_class # 筆頭IPC(sub-class)
sheet.cell(row=line,column=col_out_start+1).value = IPC_group # 筆頭IPC(main-group)
#
col_out_start = col_out_start +2
workbook.save(path+"\\"+file_name)
#
# 出願国の抽出
#
def family_analysis(file_name, sheet_name, col_family):
global path
global col_out_start
workbook = openpyxl.load_workbook(path+"\\"+file_name)
sheet = workbook.get_sheet_by_name(sheet_name)
print("Processing 出願国分析 for file = ", file_name, " sheet = ", sheet_name)
# regular expressions
regex_WO = re.compile(r'WO|WO')
regex_CN = re.compile(r'CN')
regex_US = re.compile(r'US')
regex_EP = re.compile(r'EP')
regex_KR = re.compile(r'KR')
regex_JP = re.compile(r'特|実')
# header
sheet.cell(row=1,column=col_out_start).value = 'WO'
sheet.cell(row=1,column=col_out_start+1).value = 'CN'
sheet.cell(row=1,column=col_out_start+2).value = 'US'
sheet.cell(row=1,column=col_out_start+3).value = 'EP'
sheet.cell(row=1,column=col_out_start+4).value = 'KR'
sheet.cell(row=1,column=col_out_start+5).value = 'JP'
#
for line in range(2, sheet.max_row+1):
family = sheet.cell(row=line,column=col_family).value # ファミリ出願番号(全世代)
if family is None:
sheet.cell(row=line,column=col_out_start).value = 0
sheet.cell(row=line,column=col_out_start+1).value = 0
sheet.cell(row=line,column=col_out_start+2).value = 0
sheet.cell(row=line,column=col_out_start+3).value = 0
sheet.cell(row=line,column=col_out_start+4).value = 0
sheet.cell(row=line,column=col_out_start+5).value = 0
else:
if regex_WO.search(family) is None:
sheet.cell(row=line,column=col_out_start).value = 0
else:
sheet.cell(row=line,column=col_out_start).value = 1
if regex_CN.search(family) is None:
sheet.cell(row=line,column=col_out_start+1).value = 0
else:
sheet.cell(row=line,column=col_out_start+1).value = 1
if regex_US.search(family) is None:
sheet.cell(row=line,column=col_out_start+2).value = 0
else:
sheet.cell(row=line,column=col_out_start+2).value = 1
if regex_EP.search(family) is None:
sheet.cell(row=line,column=col_out_start+3).value = 0
else:
sheet.cell(row=line,column=col_out_start+3).value = 1
if regex_KR.search(family) is None:
sheet.cell(row=line,column=col_out_start+4).value = 0
else:
sheet.cell(row=line,column=col_out_start+4).value = 1
if regex_JP.search(family) is None:
sheet.cell(row=line,column=col_out_start+5).value = 0
else:
sheet.cell(row=line,column=col_out_start+5).value = 1
#
col_out_start = col_out_start +6
workbook.save(path+"\\"+file_name)
#
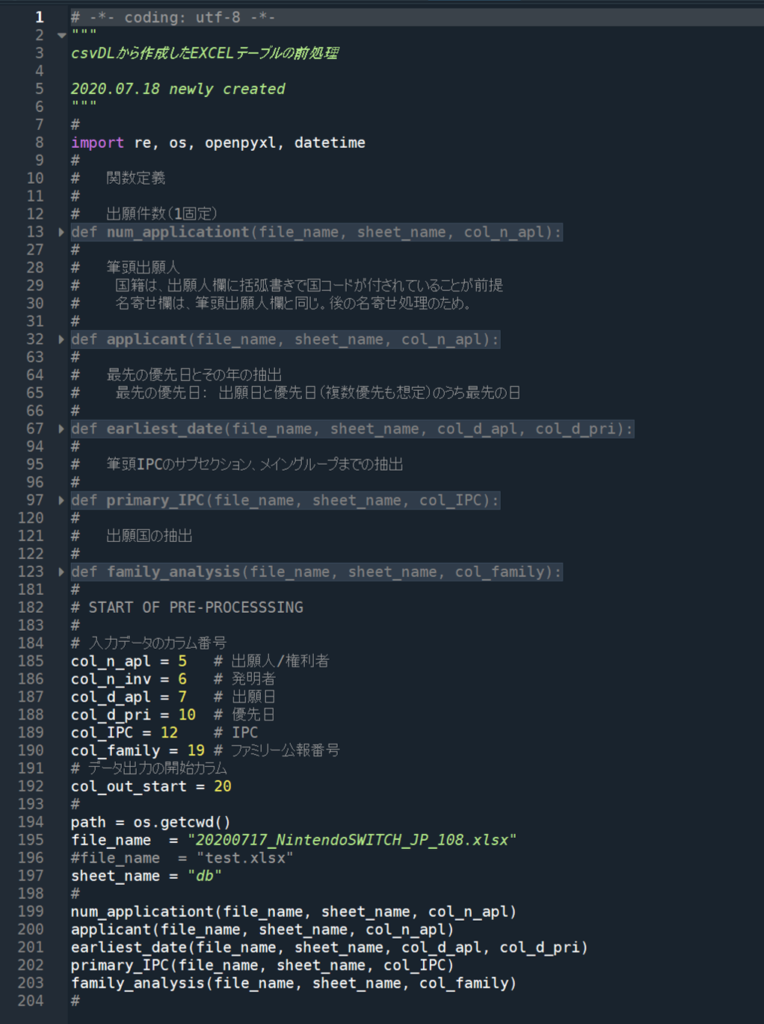
# START OF PRE-PROCESSSING
#
# 入力データのカラム番号
col_n_apl = 5 # 出願人/権利者
col_n_inv = 6 # 発明者
col_d_apl = 7 # 出願日
col_d_pri = 10 # 優先日
col_IPC = 12 # IPC
col_family = 19 # ファミリー公報番号
# データ出力の開始カラム
col_out_start = 20
#
path = os.getcwd()
file_name = "20200717_NintendoSWITCH_JP_108.xlsx"
#file_name = "test.xlsx"
sheet_name = "db"
#
num_application(file_name, sheet_name, col_n_apl)
applicant(file_name, sheet_name, col_n_apl)
earliest_date(file_name, sheet_name, col_d_apl, col_d_pri)
primary_IPC(file_name, sheet_name, col_IPC)
family_analysis(file_name, sheet_name, col_family)
#
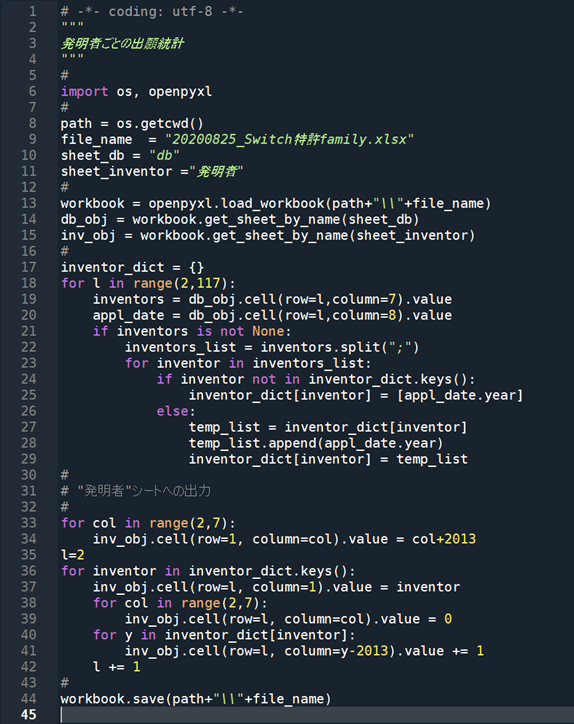
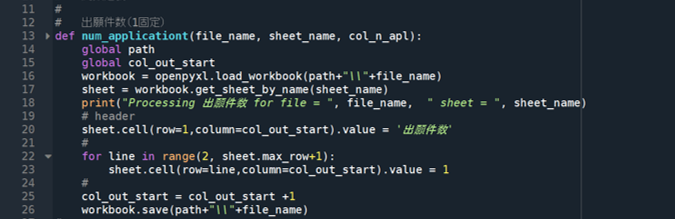
《 出願件数 num_application 関数の定義 》
#
# 出願件数(1固定)
def num_application(file_name, sheet_name, col_n_apl):
global path
global col_out_start
workbook = openpyxl.load_workbook(path+"\\"+file_name)
sheet = workbook.get_sheet_by_name(sheet_name)
print("Processing 出願件数 for file = ", file_name, " sheet = ", sheet_name)
# header
sheet.cell(row=1,column=col_out_start).value = '出願件数'
#
for line in range(2, sheet.max_row+1):
sheet.cell(row=line,column=col_out_start).value = 1
#
col_out_start = col_out_start +1
workbook.save(path+"\\"+file_name)
#
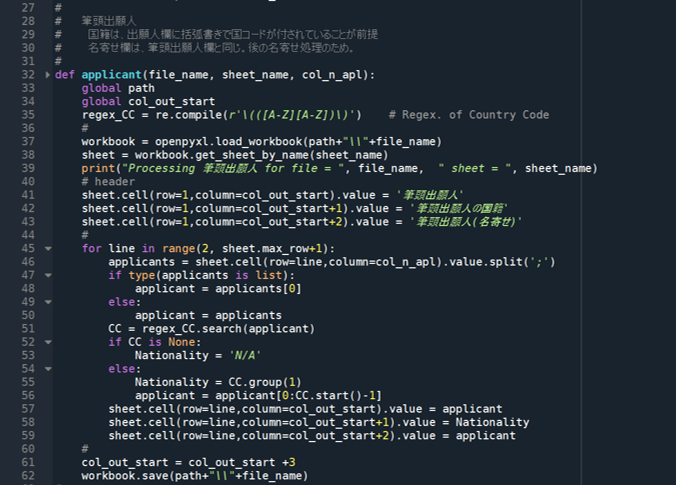
《 筆頭出願人 applicant 関数の定義 》
#
# 筆頭出願人
# 国籍は、出願人欄に括弧書きで国コードが付されていることが前提
# 名寄せ欄は、筆頭出願人欄と同じ。後の名寄せ処理のため。
#
def applicant(file_name, sheet_name, col_n_apl):
global path
global col_out_start
regex_CC = re.compile(r'\(([A-Z][A-Z])\)') # Regex. of Country Code
#
workbook = openpyxl.load_workbook(path+"\\"+file_name)
sheet = workbook.get_sheet_by_name(sheet_name)
print("Processing 筆頭出願人 for file = ", file_name, " sheet = ", sheet_name)
# header
sheet.cell(row=1,column=col_out_start).value = '筆頭出願人'
sheet.cell(row=1,column=col_out_start+1).value = '筆頭出願人の国籍'
sheet.cell(row=1,column=col_out_start+2).value = '筆頭出願人(名寄せ)'
#
for line in range(2, sheet.max_row+1):
applicants = sheet.cell(row=line,column=col_n_apl).value.split(';')
if type(applicants is list):
applicant = applicants[0]
else:
applicant = applicants
CC = regex_CC.search(applicant)
if CC is None:
Nationality = 'N/A'
else:
Nationality = CC.group(1)
applicant = applicant[0:CC.start()-1]
sheet.cell(row=line,column=col_out_start).value = applicant
sheet.cell(row=line,column=col_out_start+1).value = Nationality
sheet.cell(row=line,column=col_out_start+2).value = applicant
#
col_out_start = col_out_start +3
workbook.save(path+"\\"+file_name)
#
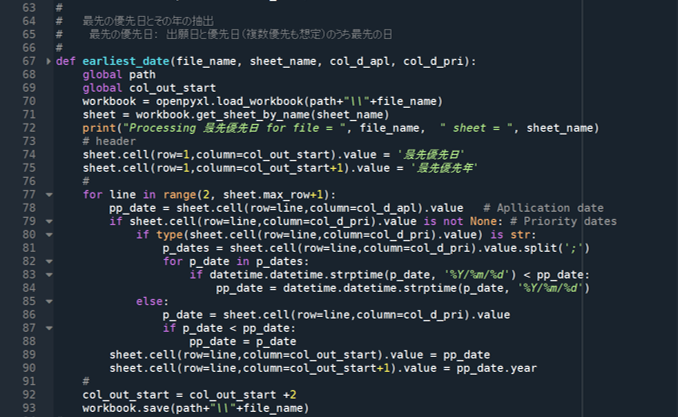
《 最先の優先日 earliest_date 関数の定義 》
#
# 最先の優先日とその年の抽出
# 最先の優先日: 出願日と優先日(複数優先も想定)のうち最先の日
#
def earliest_date(file_name, sheet_name, col_d_apl, col_d_pri):
global path
global col_out_start
workbook = openpyxl.load_workbook(path+"\\"+file_name)
sheet = workbook.get_sheet_by_name(sheet_name)
print("Processing 最先優先日 for file = ", file_name, " sheet = ", sheet_name)
# header
sheet.cell(row=1,column=col_out_start).value = '最先優先日'
sheet.cell(row=1,column=col_out_start+1).value = '最先優先年'
#
for line in range(2, sheet.max_row+1):
pp_date = sheet.cell(row=line,column=col_d_apl).value # Apllication date
if sheet.cell(row=line,column=col_d_pri).value is not None: # Priority dates
if type(sheet.cell(row=line,column=col_d_pri).value) is str:
p_dates = sheet.cell(row=line,column=col_d_pri).value.split(';')
for p_date in p_dates:
if datetime.datetime.strptime(p_date, '%Y/%m/%d') < pp_date:
pp_date = datetime.datetime.strptime(p_date, '%Y/%m/%d')
else:
p_date = sheet.cell(row=line,column=col_d_pri).value
if p_date < pp_date:
pp_date = p_date
sheet.cell(row=line,column=col_out_start).value = pp_date
sheet.cell(row=line,column=col_out_start+1).value = pp_date.year
#
col_out_start = col_out_start +2
workbook.save(path+"\\"+file_name)
#
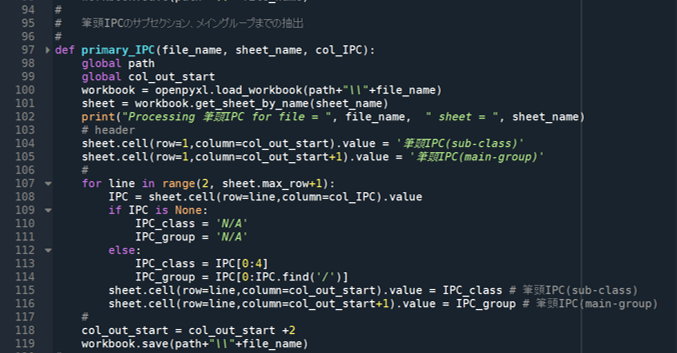
《 筆頭IPC primary_IPC 関数の定義 》
#
# 筆頭IPCのサブセクション、メイングループまでの抽出
#
def primary_IPC(file_name, sheet_name, col_IPC):
global path
global col_out_start
workbook = openpyxl.load_workbook(path+"\\"+file_name)
sheet = workbook.get_sheet_by_name(sheet_name)
print("Processing 筆頭IPC for file = ", file_name, " sheet = ", sheet_name)
# header
sheet.cell(row=1,column=col_out_start).value = '筆頭IPC(sub-class)'
sheet.cell(row=1,column=col_out_start+1).value = '筆頭IPC(main-group)'
#
for line in range(2, sheet.max_row+1):
IPC = sheet.cell(row=line,column=col_IPC).value
if IPC is None:
IPC_class = 'N/A'
IPC_group = 'N/A'
else:
IPC_class = IPC[0:4]
IPC_group = IPC[0:IPC.find('/')]
sheet.cell(row=line,column=col_out_start).value = IPC_class # 筆頭IPC(sub-class)
sheet.cell(row=line,column=col_out_start+1).value = IPC_group # 筆頭IPC(main-group)
#
col_out_start = col_out_start +2
workbook.save(path+"\\"+file_name)
#
《 出願国 family_analysis 関数の定義 》
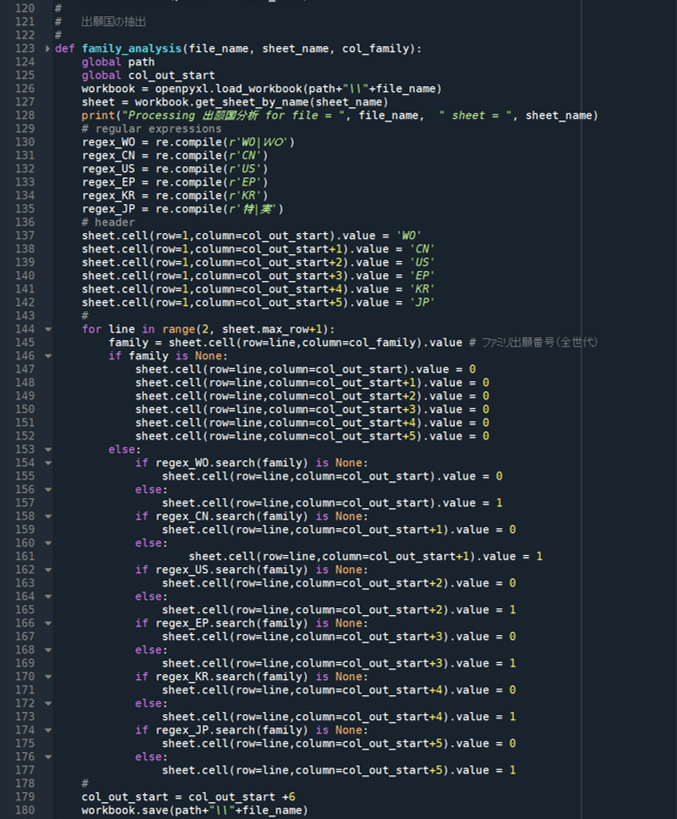
#
# 出願国の抽出
#
def family_analysis(file_name, sheet_name, col_family):
global path
global col_out_start
workbook = openpyxl.load_workbook(path+"\\"+file_name)
sheet = workbook.get_sheet_by_name(sheet_name)
print("Processing 出願国分析 for file = ", file_name, " sheet = ", sheet_name)
# regular expressions
regex_WO = re.compile(r'WO|WO')
regex_CN = re.compile(r'CN')
regex_US = re.compile(r'US')
regex_EP = re.compile(r'EP')
regex_KR = re.compile(r'KR')
regex_JP = re.compile(r'特|実')
# header
sheet.cell(row=1,column=col_out_start).value = 'WO'
sheet.cell(row=1,column=col_out_start+1).value = 'CN'
sheet.cell(row=1,column=col_out_start+2).value = 'US'
sheet.cell(row=1,column=col_out_start+3).value = 'EP'
sheet.cell(row=1,column=col_out_start+4).value = 'KR'
sheet.cell(row=1,column=col_out_start+5).value = 'JP'
#
for line in range(2, sheet.max_row+1):
family = sheet.cell(row=line,column=col_family).value # ファミリ出願番号(全世代)
if family is None:
sheet.cell(row=line,column=col_out_start).value = 0
sheet.cell(row=line,column=col_out_start+1).value = 0
sheet.cell(row=line,column=col_out_start+2).value = 0
sheet.cell(row=line,column=col_out_start+3).value = 0
sheet.cell(row=line,column=col_out_start+4).value = 0
sheet.cell(row=line,column=col_out_start+5).value = 0
else:
if regex_WO.search(family) is None:
sheet.cell(row=line,column=col_out_start).value = 0
else:
sheet.cell(row=line,column=col_out_start).value = 1
if regex_CN.search(family) is None:
sheet.cell(row=line,column=col_out_start+1).value = 0
else:
sheet.cell(row=line,column=col_out_start+1).value = 1
if regex_US.search(family) is None:
sheet.cell(row=line,column=col_out_start+2).value = 0
else:
sheet.cell(row=line,column=col_out_start+2).value = 1
if regex_EP.search(family) is None:
sheet.cell(row=line,column=col_out_start+3).value = 0
else:
sheet.cell(row=line,column=col_out_start+3).value = 1
if regex_KR.search(family) is None:
sheet.cell(row=line,column=col_out_start+4).value = 0
else:
sheet.cell(row=line,column=col_out_start+4).value = 1
if regex_JP.search(family) is None:
sheet.cell(row=line,column=col_out_start+5).value = 0
else:
sheet.cell(row=line,column=col_out_start+5).value = 1
#
col_out_start = col_out_start +6
workbook.save(path+"\\"+file_name)
#