1.文字列データ
文字列データ:シングルまたはダブルクォーテーションで囲む ’・・・・・・’ OR “・・・・・・”

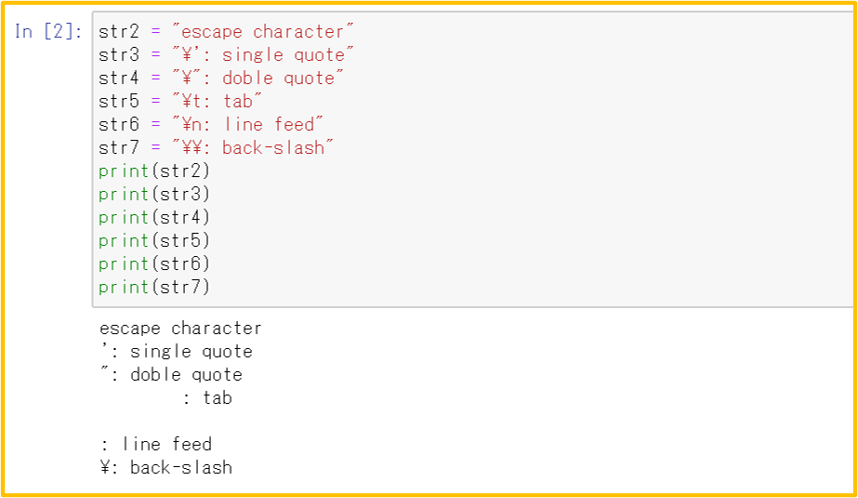
エスケープ文字
バックスラッシュ「\」+文字で特別な意味を持つ文字(制御文字など)を表す
注:バックスラッシュ「\」は円マーク「¥」で表示されることもある
| エスケープ文字 | 意味 |
|---|---|
| \’ | シングルクォーテーション |
| \” | ダブルクォーテーション |
| \t | タブ |
| \n | 改行 |
| \\ | バックスラッシュ |
raw文字列
「r」で始める
r’任意の文字列(エスケープ文字を含んでもよい)‘:そのままの文字列として扱われる

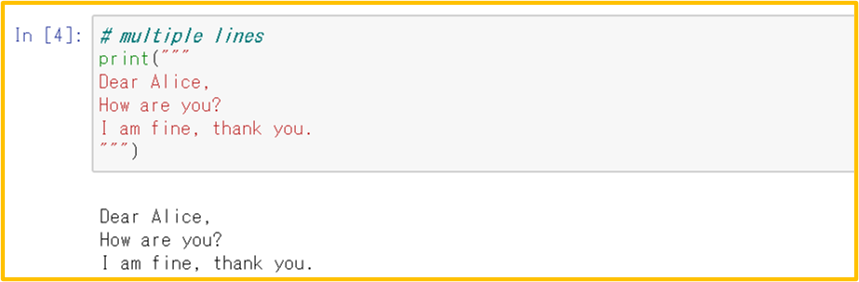
複数行
三連クォートで囲む:”””・・・複数行・・・””” OR ’’’・・・複数行・・・’’’
2. インデックスとスライス
文字列全体を、構成する各文字を要素とするリストとして扱う。インデックスを使って文字単位、スライスを使って複数文字の範囲単位でアクセスできる。
| 文字列 | H | e | l | l | o | w | o | r | l | d | ! | |
| インデックス | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |

3.文字列データに対する演算
演算
+ : 結合、*:繰り返し

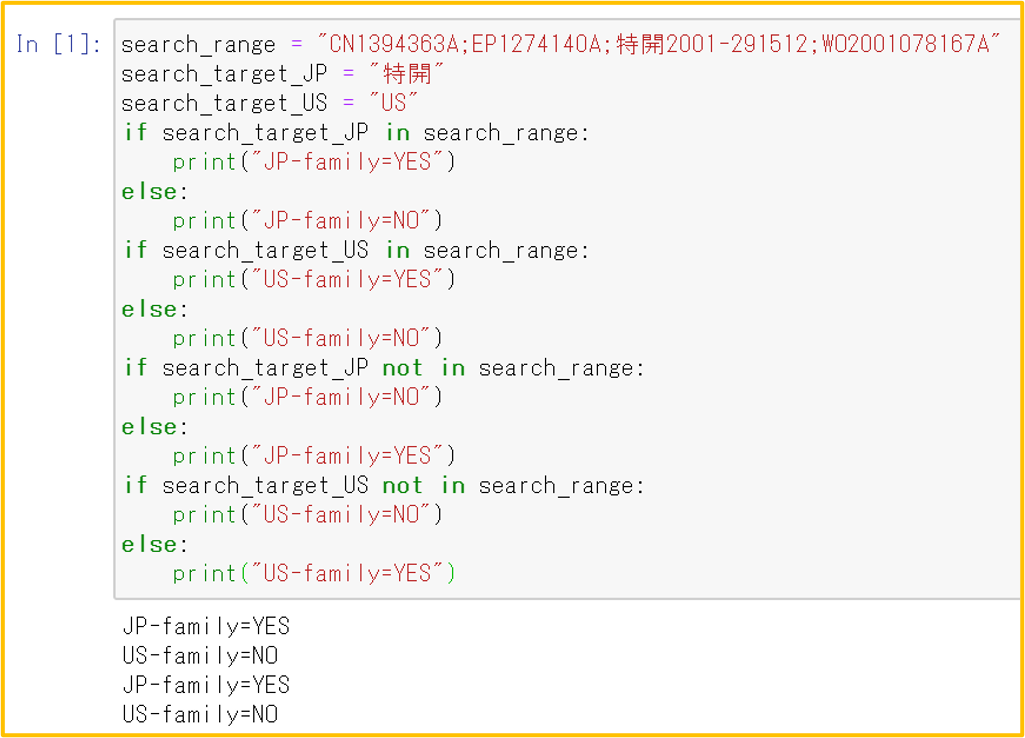
in / not in 演算
検査文字列 in 検査対象文字列 ⇒ 戻り値=True/False
検査文字列 not in 検査対象文字列 ⇒ 戻り値=True/False
4. メソッド(文字列データ専用の関数のようなもの)
| メソッド | 内容 |
|---|---|
| upper() | 大文字に変換 |
| lower() | 小文字に変換 |
| isupper() | (検査) すべてが大文字のときTrue |
| islower() | (検査) すべてが小文字のときTrue |
| isalpha() | (検査) すべてが英文字のときTrue |
| isalnum() | (検査) すべてが英字または数字のときTrue |
| isdecimal() | (検査) すべてが数字のときTrue |
| isspace() | (検査) すべてがスペース、タブまたは改行のときTrue |
| istitle() | (検査) 大文字から始まり他が小文字の単語で構成されているときTrue |
| startswith(検査値) | (検査) 検査値の文字列から始まるときTrue |
| endswith(検査値) | (検査) 検査値の文字列で終わるときTrue |
| rjust(文字数[,文字]) | (整形) 指定した文字数に右詰、他は指定した文字*1)で埋める |
| ljust(文字数[,文字]) | (整形) 指定した文字数に左詰、他は指定した文字*1)で埋める |
| center(文字数[,文字]) | (整形) 指定した文字数に中央揃え、他は指定した文字*1)で埋める |
| rstrip([文字]) | (整形) 右端から指定した文字*2)を除去 |
| lstrip([文字]) | (整形) 左端から指定した文字*2)を除去 |
| strip([文字]) | (整形) 両端から指定した文字*2)を除去 |
*2):[文字]は複数の文字を指定してよい。文字列ではなく順不同の各文字として扱う
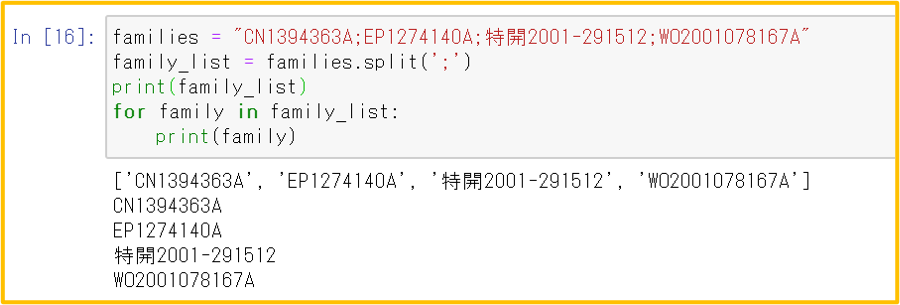
split()メソッド
対象の文字列を、指定した文字で分割して、リストを返す
例:特許ファミリー ”CN1394363A;EP1274140A;特開2001-291512;WO2001078167A” は、セミコロン”;”で区切られているので、split(“;”)を使うと各国公報番号のリストを得られる
この例の他、以下のような例がある
・複数行の文章から、改行マークによって段落ごとにわけたリストを作成
・複数行の文章から、ピリオド+空白によって文ごとにわけたリストを作成
join()メソッド
リストで与えられる複数の文字列を指定する文字で連結して、長い文字列を返す
例:上の例の逆に、family_listがあるときに、指定した文字(例えば「と、」)で連結する]

replace()メソッド
対象の文字列に含まれる「検査文字列」を「置換文字列」に置き換える

「改行」など特殊な文字(列)も扱える