正規表現(regular expression)(末尾のまとめ表)を使った、高機能な文字列
1. 一般的な流れ
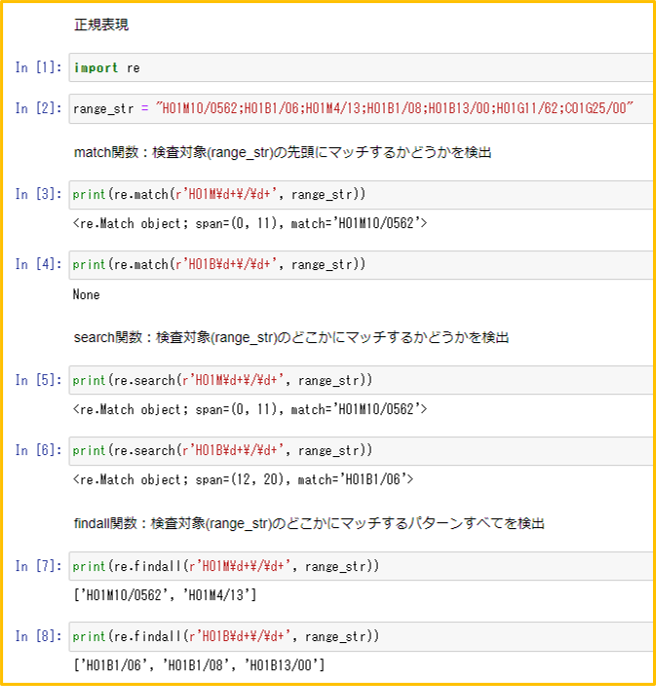
1.1 関数
- ”re”モジュールをインポート:import re
- プログラム中に関数
match関数: re.match(r’ 正規表現’, 検査対象文字列)
戻り値 ⇒ 先頭が一致なら一致した文字列/不一致ならNONE
search関数: re.search(r’ 正規表現’, 検査対象文字列)
戻り値 ⇒ 検査対象文字列中の正規表現に合致する文字列/不一致ならNONE
findall関数: re.findall(r’ 正規表現’, 検査対象文字列)
戻り値 ⇒ 検査対象文字列中の正規表現に合致する全文字列のリスト
オブジェクトを構成するspan( 始点 , 終点 )とmatch(マッチしたパターン)を取得する
始点:re.search(r’ 正規表現’, 検査対象文字列) .start()
終点:re.search(r’ 正規表現’, 検査対象文字列) .end()
span:re.search(r’ 正規表現’, 検査対象文字列) .span()
マッチしたパターン:re.search(r’ 正規表現’, 検査対象文字列) .group()
マッチしたパターンのリスト:re.search(r’ 正規表現’, 検査対象文字列) .groups()
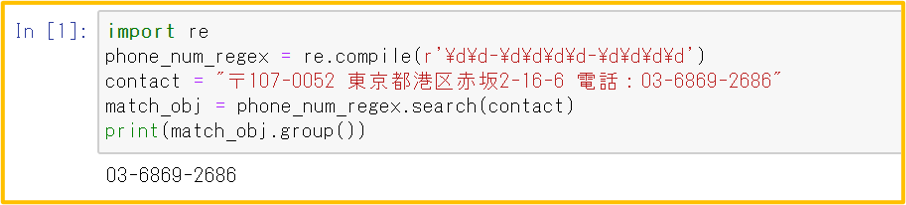
1.2 searchメソッド:正規表現に合致する文字列を取得する
- ”re”モジュールをインポート:import re
- Regexオブジェクトを生成:re_obj = re.compile(正規表現)
- Regexオブジェクトにsearch(検索対象文字列)メソッドを作用させてMatchオブジェクトを返す:match_obj = re_obj.search(‘検索対象文字列’)
(’検索対象文字列’の中で、2の正規表現に一致する部分をMatchオブジェクトとして返す) - group()メソッドを使って、Matchオブジェクトからマッチした文字列を取得:match_obj.group()
市外局番は多数桁もあり、局番も1~4桁までいろいろある。さらにハイフン「-」ではなくカッコ「(局番)」が使われる場合もある。正規表現なら複雑な表現にも対応可能。
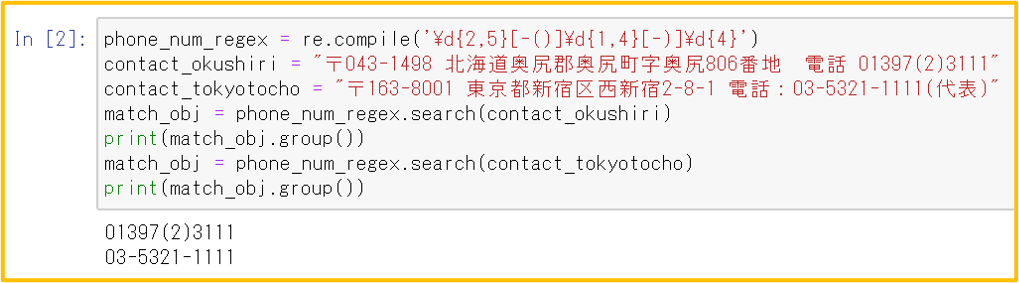
[-()]: 「-」「(」「)」のうちのいずれか1文字
\d{1,4}: 1~4桁の数字
[-)]: 「-」「)」のうちのいずれか1文字
\d{4}: 4桁の数字
(詳しくは、「まとめ表」を参照)
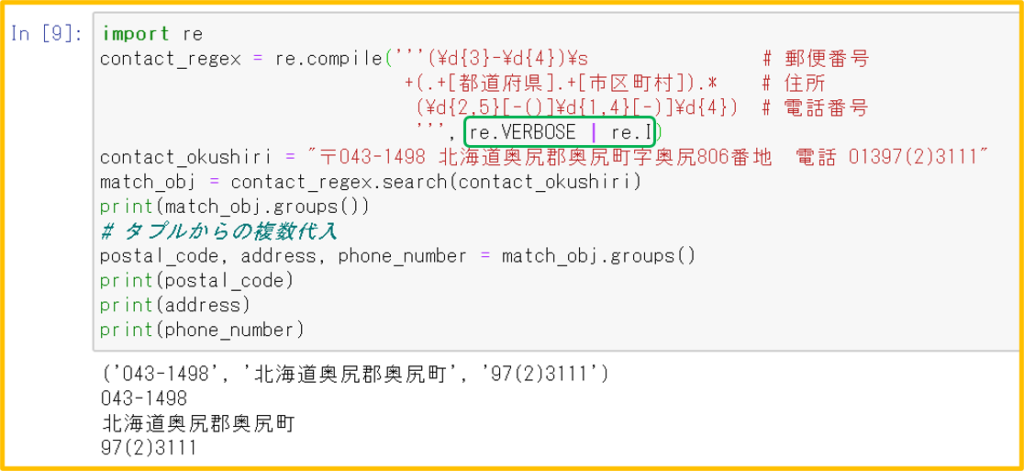
2. group()メソッド、groups()メソッド
複数のパターンマッチングを並行に行う
複数のグループを含む正規表現を定義・・・カッコ( )でグルーピング
match_obj.group(数字)で、マッチしたグループを個別に参照
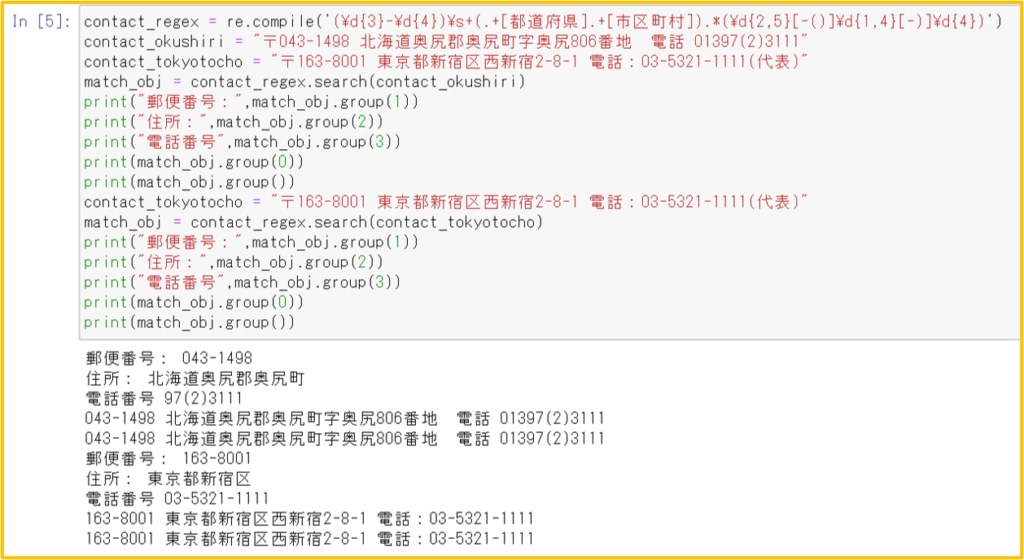
groups()メソッドを使えば、マッチした複数のグループをタプル形式で取得できる
タプルから変数への複数代入を使えば、1行のコマンドで複数の変数に代入できる
3. 貪欲マッチ(greedy match)/非貪欲マッチ
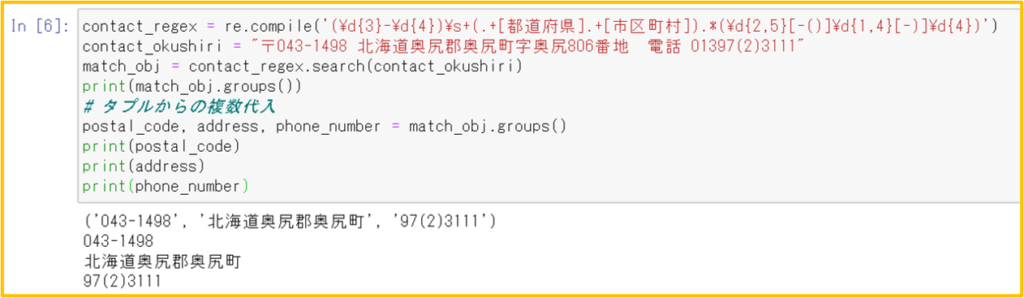
貪欲マッチ(greedy match):ある正規表現にマッチする複数のパターン(文字列)があるときに、最も長いものがマッチとして扱われる(デフォルト)
非貪欲マッチ:ある正規表現にマッチする複数のパターン(文字列)があるときに、最も長いものがマッチとして扱われる(正規表現の後ろに「」を付ける)
例:
正規表現:(Ha){3,5}
検査対象:HaHaHaHaHa
Haが3回、4回、5回の三通り、さらに3回、4回なら位置も含めれば、6通りのマッチパターンがあるが、貪欲マッチでは最も長いものがマッチとして扱われる。
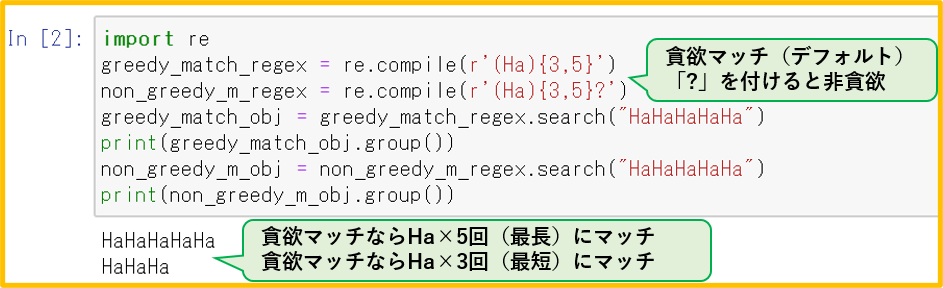
4. findall()メソッド
search()メソッドが、最初にマッチした文字列のmatchオブジェクトを返すのに対して、
findall()メソッドは、マッチしたすべての文字列をタプル形式で返す。

5. sub()メソッド
正規表現にマッチした文字列の置換。
regex_obj = re.compile(正規表現)
regex_obj.sub(変換先, 変換対象のテキスト)

マッチした一部を再利用した置換
regex_obj = re.compile(括弧()を使った正規表現) # group参照
regex_obj.sub(変換先(マッチした順に\1, \2, \3を使って表現), 変換対象のテキスト)

6. オプション
6.1 re.IGNORECASEオプション:大文字/小文字を無視したマッチ
re.IGNORECASE (re.Iと省略可) オプションの指定により、大文字と小文字を区別しないでマッチを探す探索ができる。

6.2 re.DOTALLオプション:ドット「.」文字を改行にもマッチ
ドット「.」は、改行を除く任意の1文字にマッチする(「まとめ表」参照)が、
re.DOTALLオプションを指定することによって、改行を含む任意の1文字にマッチさせることができる。
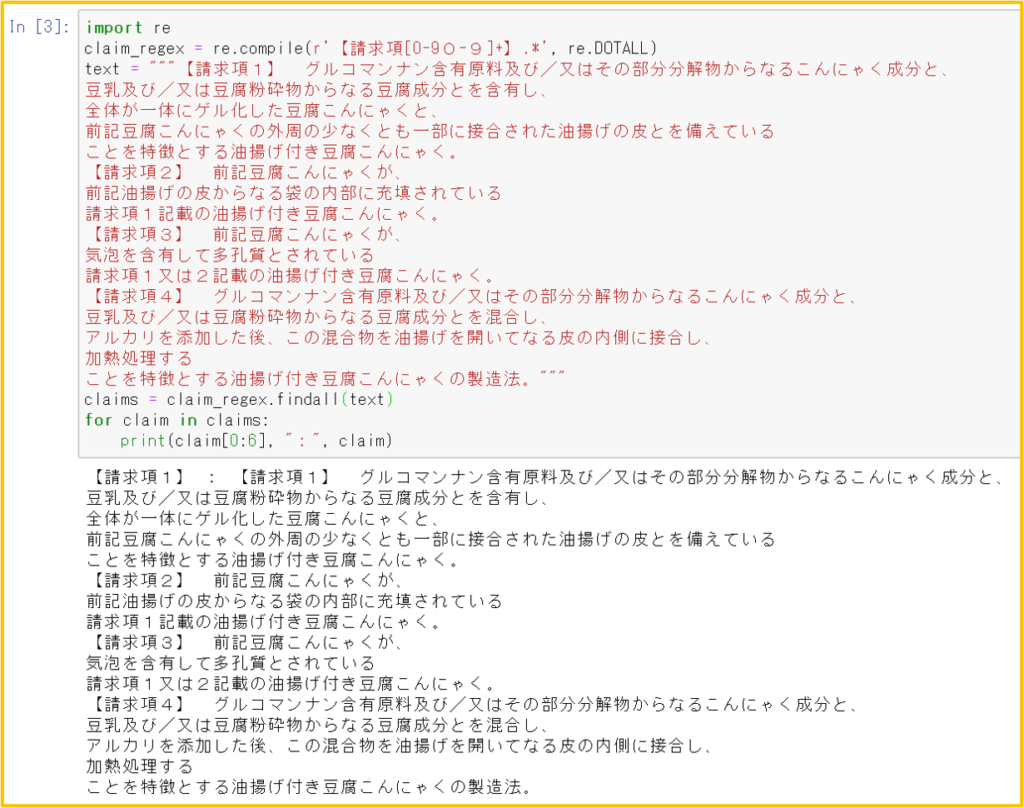
請求項には、改行が含まれることがよくある。墨付け括弧【請求項n】をキーワードとして分離したいが、DOTALLオプションの効果で【請求項n】もマッチしてしまい、末尾まですべてが請求項1になってしまった。
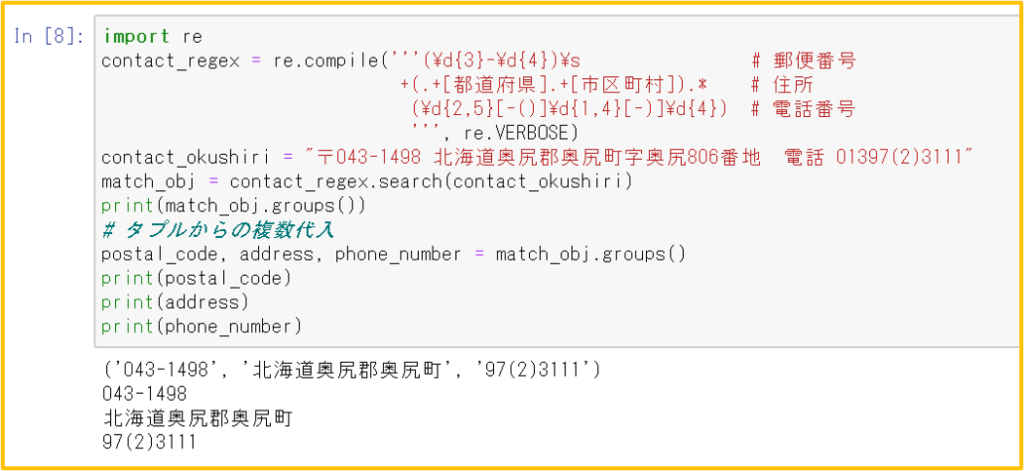
6.3 re.VERBOSEオプション:正規表現を複数行にわけてコメント
長く複雑な正規表現を複数行に分けて記述して、それぞれの行にコメントをつけて、わかりやすくする。複数行にまたがるため三連クォートを使う。
6.4 複数のオプション
縦棒「|」で並列表記。re.compileの引数の数は限られているので、第2引数にORで指定するイメージ。
まとめ表
| 短縮形、記号 | 意味 |
|---|---|
| \d | 0~9の数字 |
| \D | 0~9の数字以外 |
| \w | 文字、数字、下線(”_”) |
| \W | {文字、数字、下線(”_”)}以外 |
| \s | スペース、タブ、改行 |
| \S | {スペース、タブ、改行}以外 |
| ^ | 先頭 ex.: ^\d :0~9の数字から始まる文字列 |
| $ | 末尾 ex.: \d$ :0~9の数字で終わる文字列 |
| .(ドット) | 任意の1文字(改行を除く) |
| \n | 改行 |
| \t | タブ |
| ? | 直前のグループの 0~1回の出現にマッチ ex.: \d?=0-1桁の数字 |
| * | 直前のグループの 0回以上の出現にマッチ ex.: \d*=0桁以上の数字 |
| + | 直前のグループの 1回以上の出現にマッチ ex.: \d*=1桁以上の数字 |
| [複数文字] | 複数文字の中のいずれか1文字にマッチ ex.: [a-z]=小文字の英字 |
| [^複数文字] | 複数文字以外の1文字にマッチ ex.: [^a-z]=小文字の英字以外 |
| |(縦棒) | 複数グループのうちの1つにマッチ ex.: [a-z]|[0-9]=小文字の英字or数字 |
| {n} | 直前のグループのn回の出現にマッチ ex.: \d{4}=4桁の数字 |
| {n,m} | 直前のグループのn~m回の出現にマッチ ex.: \d{4,6}=4-6桁の数字 |
| {n,} | 直前のグループのn回以上の出現にマッチ ex.: \d{4,}=4桁以上の数字 |
| {,m} | 直前のグループの0~m回の出現にマッチ ex.: \d{,6}=0-6桁の数字 |