〘 背景 〙
日本の特許文献には、FIとFタームと呼ばれる特許分類が付与されている。FIは国際特許分類(IPC)と同じ階層構造で、日本の実情に合わせて細分化されている。Fタームは、テーマコードごとに種々の観点について付与された特許分類コードである。出願された特許文献の内容に応じて付与されるので、内容を読む代わりに付与されているFIやFタームを分析対象とすることで、特許文献の内容分析ができる。リチウムイオン電池の電極材料の特許マップ
〘 課題 〙
1件の特許文献には複数の(多くの)特許分類コードが付与されている。前処理として、どのコードが付与されているかを表すフラグを立てる。分析対象の特許文献それぞれにフラグを立てる処理をしておけば、後段に分析目的に合わせた集計処理を行えば良い。
〘 仕様 〙
処理対象:EXCELの特許文献リスト()
入力
「Fターム」カラム5H050 AA02;5H050 AA08;5H050 BA17;5H050 CA08;5H050 CA09;5H050 CB01;5H050 CB02;5H050 CB08;5H050 CB11;5H050 DA03;5H050 DA04;5H050 DA10;5H050 DA11;5H050 DA18;5H050 EA23;5H050 EA24;5H050 EA28;5H050 FA02;5H050 FA17;5H050 GA10;5H050 HA00;5H050 HA01;5H050 HA20 ”
出力
フラグを立てる複数のカラム1/” “ )
注:フラグを立てる対象のFタームが上位階層なら、それに含まれる下位階層のFタームでもフラグが立つようにプログラミングする。但し、階層関係はプログラマーが解釈してソースコード内に正規表現
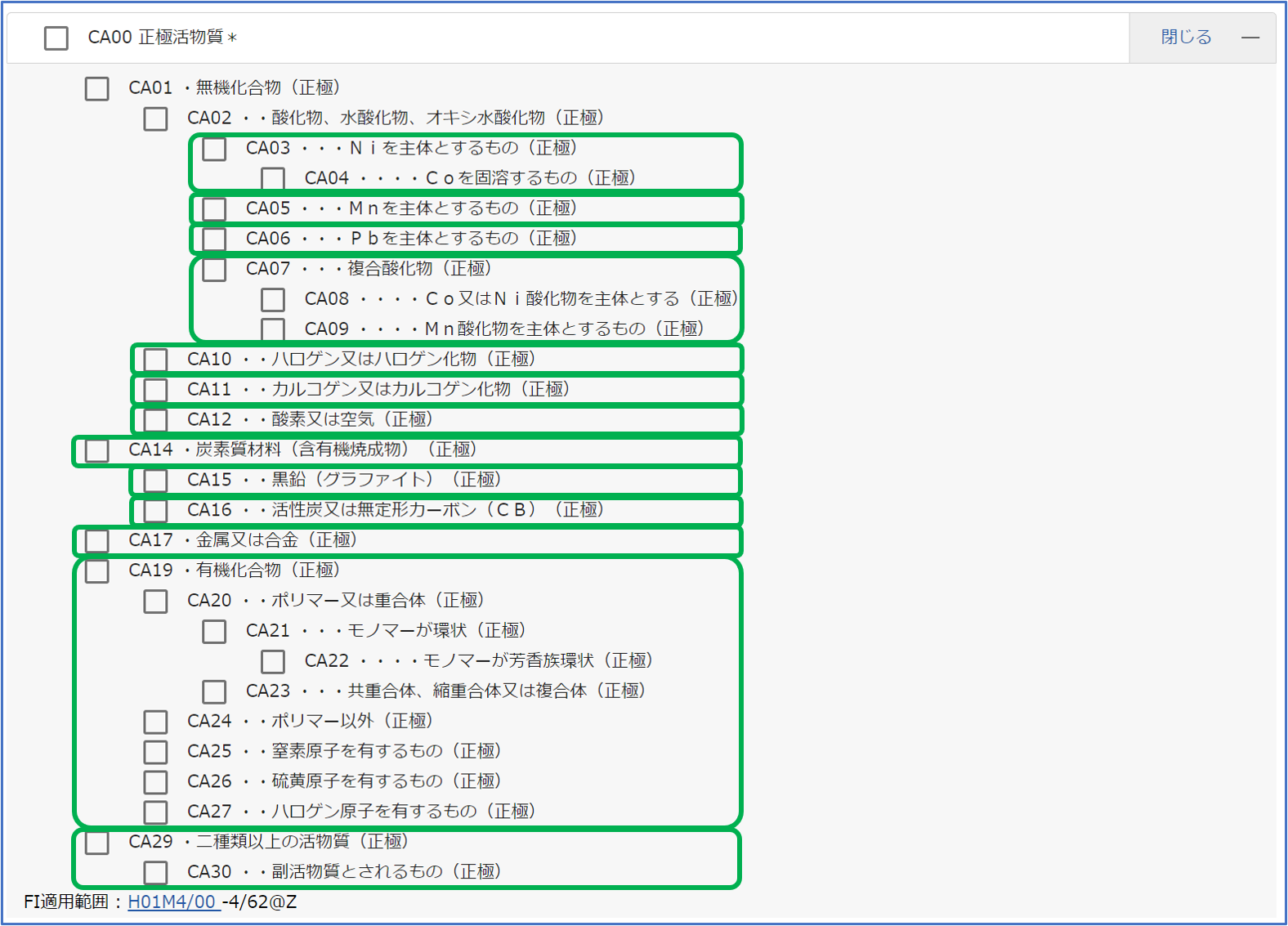
〘 階層構造を考慮した正規表現〙
Fタームの階層構造の例は、以下のとおり。上述の「リチウムイオン電池の電極材料の特許マップ」で分析対象としたテーマコード「電池の電極および活物質」(5H050)の「正極活物質」(CA00)である。
フラグを立てたい範囲を緑の枠取りで示す。フラグを立てたい範囲を正規表現で表す(各正規マッチマッチオブジェクトを生成する)。
例1:CA03(Niを主体とするもの)の下位概念にはCA04(Coを固溶するもの)を下位に含むので、CA03 or CA04が付与されていればCA03のフラグ(CA01)を立てる。
CA01 = re.compile(‘5H050 (CA03|CA04)’)
例2:CA19(有機化合物)の下位概念にはCA20(ポリマーまたは重合体)~CA27(ハロゲン原子を有するもの)を下位に含むので、CA19 ~ CA27が付与されていればCA19のフラグ(CA12)を立てる。
CA12 = re.compile(‘5H050 (CA19|CA2[0-7])’)
フラグを立てたいすべてのFタームについて、マッチオブジェクトを生成する。
〘 各レコード(特許文献)についてフラグを立てる 〙
searchメソッドを使って、マッチオブジェクトにマッチするパターンが、対象レコード(特許文献)のFタームカラムの文字列に含まれているかを判定し(if文)、EXCELの所定カラムに出力する。
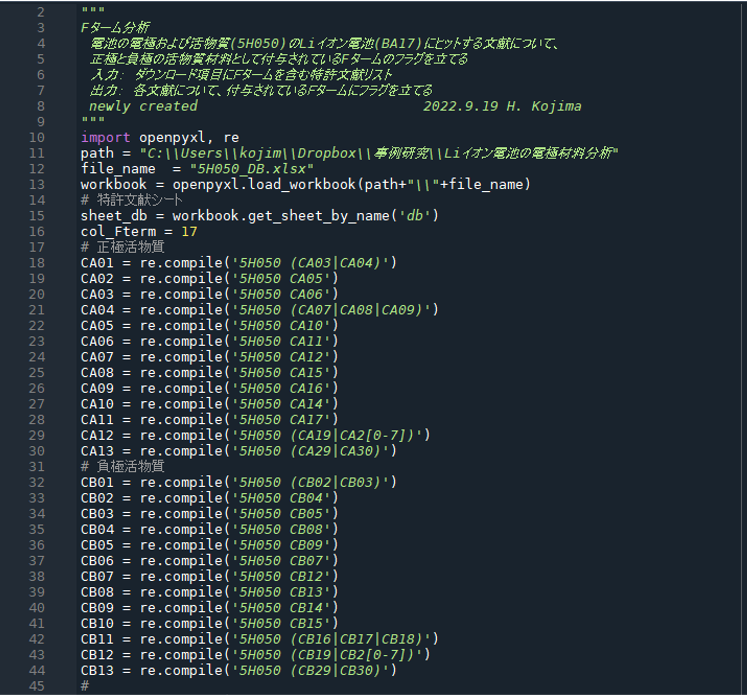
〘 ソースコード 〙
# -*- coding: utf-8 -*-
"""
Fターム分析
電池の電極および活物質(5H050)のLiイオン電池(BA17)にヒットする文献について、
正極と負極の活物質材料として付与されているFタームのフラグを立てる
入力: ダウンロード項目にFタームを含む特許文献リスト
出力: 各文献について、付与されているFタームにフラグを立てる
newly created 2022.9.19 H. Kojima
"""
import openpyxl, re
path = "C:\\Users\\kojim\\Dropbox\\事例研究\\Liイオン電池の電極材料分析"
file_name = "5H050_DB.xlsx"
workbook = openpyxl.load_workbook(path+"\\"+file_name)
# 特許文献シート
sheet_db = workbook.get_sheet_by_name('db')
col_Fterm = 17
# 正極活物質
CA01 = re.compile('5H050 (CA03|CA04)')
CA02 = re.compile('5H050 CA05')
CA03 = re.compile('5H050 CA06')
CA04 = re.compile('5H050 (CA07|CA08|CA09)')
CA05 = re.compile('5H050 CA10')
CA06 = re.compile('5H050 CA11')
CA07 = re.compile('5H050 CA12')
CA08 = re.compile('5H050 CA15')
CA09 = re.compile('5H050 CA16')
CA10 = re.compile('5H050 CA14')
CA11 = re.compile('5H050 CA17')
CA12 = re.compile('5H050 (CA19|CA2[0-7])')
CA13 = re.compile('5H050 (CA29|CA30)')
# 負極活物質
CB01 = re.compile('5H050 (CB02|CB03)')
CB02 = re.compile('5H050 CB04')
CB03 = re.compile('5H050 CB05')
CB04 = re.compile('5H050 CB08')
CB05 = re.compile('5H050 CB09')
CB06 = re.compile('5H050 CB07')
CB07 = re.compile('5H050 CB12')
CB08 = re.compile('5H050 CB13')
CB09 = re.compile('5H050 CB14')
CB10 = re.compile('5H050 CB15')
CB11 = re.compile('5H050 (CB16|CB17|CB18)')
CB12 = re.compile('5H050 (CB19|CB2[0-7])')
CB13 = re.compile('5H050 (CB29|CB30)')
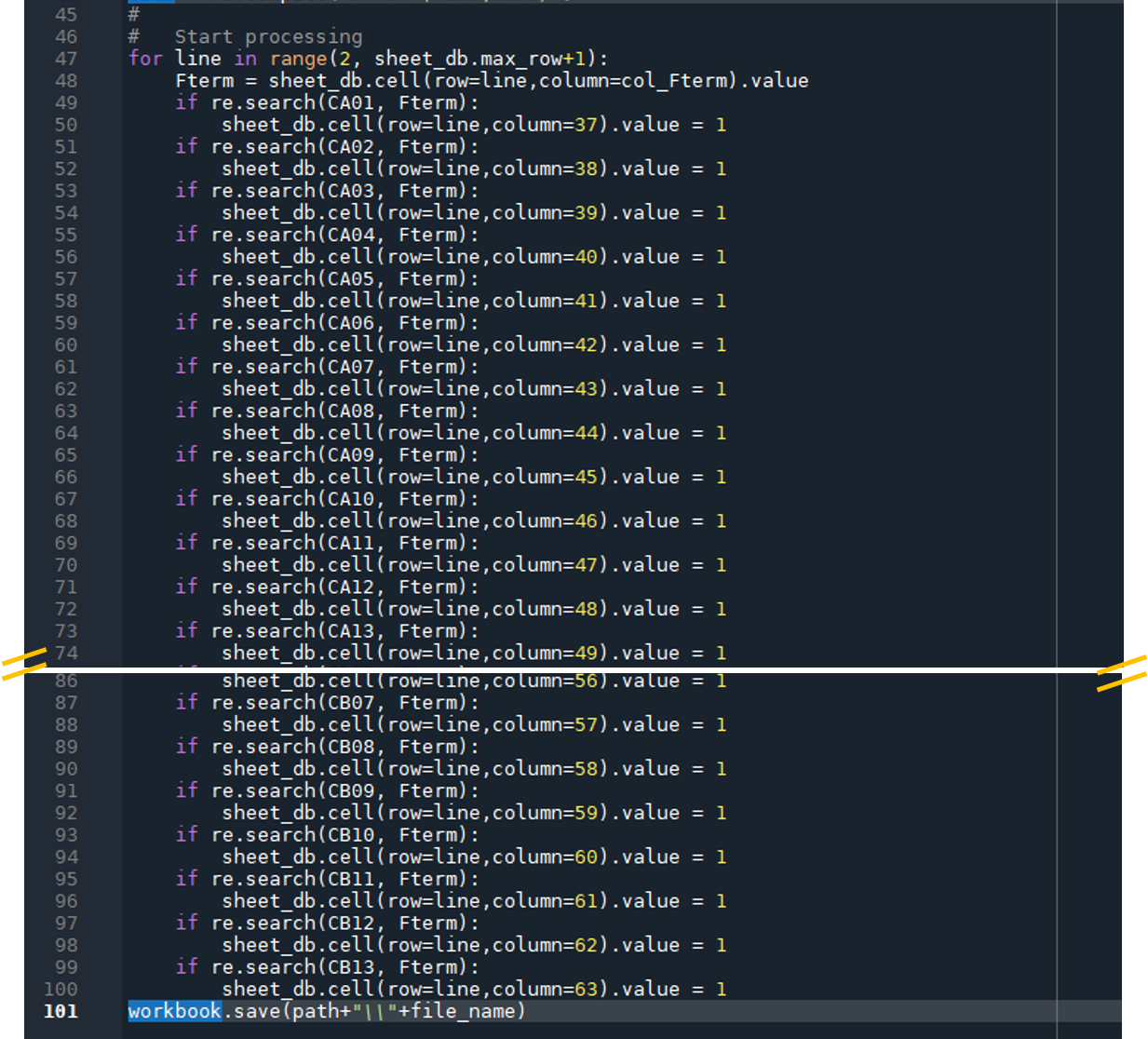
#
# Start processing
for line in range(2, sheet_db.max_row+1):
Fterm = sheet_db.cell(row=line,column=col_Fterm).value
if re.search(CA01, Fterm):
sheet_db.cell(row=line,column=37).value = 1
if re.search(CA02, Fterm):
sheet_db.cell(row=line,column=38).value = 1
if re.search(CA03, Fterm):
sheet_db.cell(row=line,column=39).value = 1
if re.search(CA04, Fterm):
sheet_db.cell(row=line,column=40).value = 1
if re.search(CA05, Fterm):
sheet_db.cell(row=line,column=41).value = 1
if re.search(CA06, Fterm):
sheet_db.cell(row=line,column=42).value = 1
if re.search(CA07, Fterm):
sheet_db.cell(row=line,column=43).value = 1
if re.search(CA08, Fterm):
sheet_db.cell(row=line,column=44).value = 1
if re.search(CA09, Fterm):
sheet_db.cell(row=line,column=45).value = 1
if re.search(CA10, Fterm):
sheet_db.cell(row=line,column=46).value = 1
if re.search(CA11, Fterm):
sheet_db.cell(row=line,column=47).value = 1
if re.search(CA12, Fterm):
sheet_db.cell(row=line,column=48).value = 1
if re.search(CA13, Fterm):
sheet_db.cell(row=line,column=49).value = 1
if re.search(CB01, Fterm):
sheet_db.cell(row=line,column=51).value = 1
if re.search(CB02, Fterm):
sheet_db.cell(row=line,column=52).value = 1
if re.search(CB03, Fterm):
sheet_db.cell(row=line,column=53).value = 1
if re.search(CB04, Fterm):
sheet_db.cell(row=line,column=54).value = 1
if re.search(CB05, Fterm):
sheet_db.cell(row=line,column=55).value = 1
if re.search(CB06, Fterm):
sheet_db.cell(row=line,column=56).value = 1
if re.search(CB07, Fterm):
sheet_db.cell(row=line,column=57).value = 1
if re.search(CB08, Fterm):
sheet_db.cell(row=line,column=58).value = 1
if re.search(CB09, Fterm):
sheet_db.cell(row=line,column=59).value = 1
if re.search(CB10, Fterm):
sheet_db.cell(row=line,column=60).value = 1
if re.search(CB11, Fterm):
sheet_db.cell(row=line,column=61).value = 1
if re.search(CB12, Fterm):
sheet_db.cell(row=line,column=62).value = 1
if re.search(CB13, Fterm):
sheet_db.cell(row=line,column=63).value = 1
workbook.save(path+"\\"+file_name)
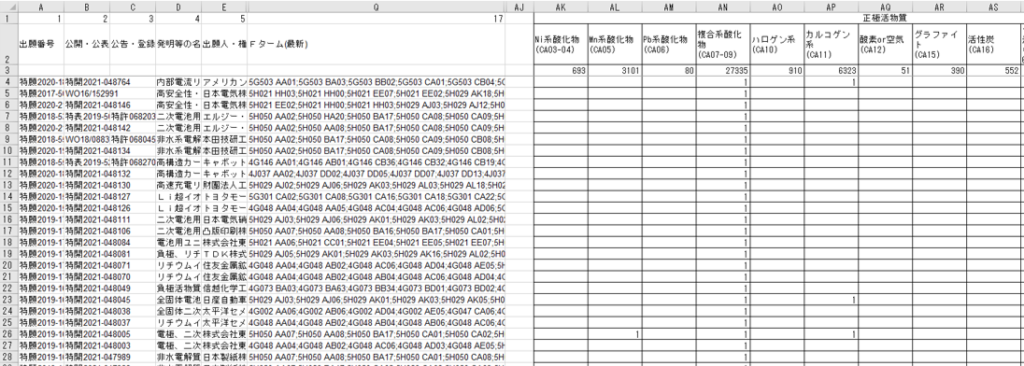
〘 出力(フラグを出力したEXCELの カラム)〙